
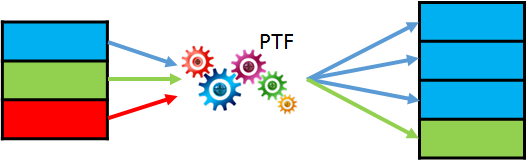
In the third part of the PTF-series we learn how a PTF can change the cardinality of the input data flow: return more or less rows as in the input. We’ll use the same simple table as in the part 2 and our new task will be column transposing. We’ll still define, which columns have to stay unchanged (as we already did using the parameter cols2stay). All other columns should be displayed as key-value pairs.
Figure 1 shows what we are trying to achieve. What is different in this task compared to those from the first and second part? Looking at the picture you immediately see that: for each input row we have to produce as many output rows as there are columns to transpose. And this is quite dynamic dependent on the parameter cols2stay.
So we should be able to replicate input rows 0 to N times. Fortunately, PTFs are able to do such replication by design. First, we have to tell the database that we are going to use replication using DESCRIBE method. Then we can specify both a fixed factor for all rows in a rowset, as well as a separate one for each row.
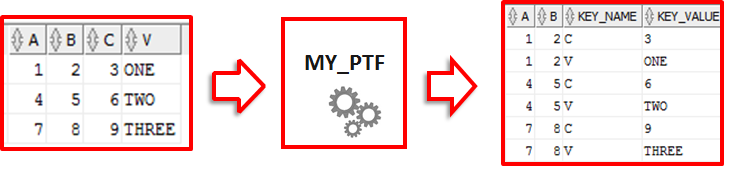
Figure 1: Transpose all but selected identifying columns
Let’s do it! The DESCRIBE method looks already familiar. Now we define two new columns with hard-coded column names KEY_NAME and KEY_VALUE. But the important difference is that we set the replication flag to TRUE on line 33. This flag is a part of the record type DBMS_TF.DESCRIBE_T. If you forget to set this flag and try to use replication later in FETCH_ROWS, you’ll get an error ORA-62574: row replication flag was not set.
CREATE OR REPLACE PACKAGE tab2keyval_pkg AS
FUNCTION describe (tab IN OUT dbms_tf.table_t
, cols2stay IN dbms_tf.columns_t )
RETURN dbms_tf.describe_t;
PROCEDURE fetch_rows;
END tab2keyval_pkg;
/
CREATE OR REPLACE PACKAGE BODY tab2keyval_pkg AS
FUNCTION describe (tab IN OUT dbms_tf.table_t
, cols2stay IN dbms_tf.columns_t )
RETURN dbms_tf.describe_t IS
BEGIN
FOR I IN 1 .. tab.COLUMN.COUNT LOOP
IF NOT tab.COLUMN(i).description.name MEMBER OF cols2stay THEN
tab.column(i).pass_through := false;
tab.column(i).for_read := true;
END IF;
END LOOP;
RETURN dbms_tf.describe_t(new_columns =>
dbms_tf.columns_new_t(
1 => dbms_tf.column_metadata_t(
name => 'KEY_NAME'
, type => dbms_tf.type_varchar2),
2 => dbms_tf.column_metadata_t(
name => 'KEY_VALUE'
, type => dbms_tf.type_varchar2)),
row_replication => true);
END;
...
Listing 1: DESCRIBE method
Now that we told the database that we intend to use row replication, how do we do that? There is an overloaded procedure for this: dbms_tf.row_replication. You can pass a number of PL/SQL type NATURALN as a fixed factor for all rows or use table of NATURALN with factor values for individual rows. In our example, we’ll be using the table (variable repfac of the type dbms_tf.tab_naturaln_t on line 4)
We’ve already seen, how to fetch a rowset using dbms_tf.get_row_set. While looping through rows and columns we increment the value of the factor per one for each column to transpose.
To get the name of the column we are using the environment record of the type ENV_T which we’ve already seen in the second part. Note that columns names are enclosed in quotation marks. After filling collections with data and replication factors we call the procedure dbms_tf.row_replication and then “put” the collections for put-columns.
...
PROCEDURE fetch_rows IS
rowset dbms_tf.row_set_t;
repfac dbms_tf.tab_naturaln_t;
rowcnt PLS_INTEGER;
colcnt PLS_INTEGER;
name_col dbms_tf.tab_varchar2_t;
val_col dbms_tf.tab_varchar2_t;
env dbms_tf.env_t := dbms_tf.get_env();
BEGIN
dbms_tf.get_row_set(rowset, rowcnt, colcnt);
FOR r IN 1..rowcnt LOOP
repfac(r) := 0;
FOR c IN 1..colcnt LOOP
repfac(r) := repfac(r) + 1;
name_col(nvl(name_col.last+1,1)) :=
INITCAP( regexp_replace(env.get_columns(c).name, '^"|"$'));
val_col(nvl(val_col.last+1,1)) := DBMS_TF.COL_TO_CHAR(rowset(c), r);
END LOOP;
END LOOP;
dbms_tf.row_replication(replication_factor => repfac);
dbms_tf.put_col(1, name_col);
dbms_tf.put_col(2, val_col);
END;
END tab2keyval_pkg;
/
CREATE OR REPLACE FUNCTION tab2keyval (tab TABLE, cols2stay COLUMNS )
RETURN TABLE PIPELINED ROW POLYMORPHIC USING tab2keyval_pkg;
/
SQL> SELECT * FROM tab2keyval(t, COLUMNS(A,B));
A B KEY_NAME KEY_VALUE
---------- ---------- ---------- --------------------
1 2 C 3
1 2 V "ONE"
4 5 C 6
4 5 V "TWO"
7 8 C 9
7 8 V "THREE"
6 rows selected.
Listing 2: FETCH_ROWS method
Be very careful assigning values to the elements of the associative array repfac. Don’t forget to assign the value (like on line 13) before using it for the first time (line 15, on the right side of the assignment). Otherwise you’ll get a NO_DATA_FOUND exception. And that seems to be e special one for PTF, because it will be silently ignored. Look at Listing 3. I’ll show only the procedure FETCH_ROWS, where I commented out the initial assignment and built in an exception handler.
...
PROCEDURE fetch_rows IS
rowset dbms_tf.row_set_t;
repfac dbms_tf.tab_naturaln_t;
rowcnt PLS_INTEGER;
colcnt PLS_INTEGER;
name_col dbms_tf.tab_varchar2_t;
val_col dbms_tf.tab_varchar2_t;
env dbms_tf.env_t := dbms_tf.get_env();
BEGIN
dbms_tf.get_row_set(rowset, rowcnt, colcnt);
FOR r IN 1..rowcnt LOOP
-- repfac(r) := 0;
FOR c IN 1..colcnt LOOP
repfac(r) := repfac(r) + 1;
name_col(nvl(name_col.last+1,1)) :=
INITCAP( regexp_replace(env.get_columns(c).name, '^"|"$'));
val_col(nvl(val_col.last+1,1)) := DBMS_TF.COL_TO_CHAR(rowset(c), r);
END LOOP;
END LOOP;
dbms_tf.row_replication(replication_factor => repfac);
dbms_tf.put_col(1, name_col);
dbms_tf.put_col(2, val_col);
END;
END tab2keyval_pkg;
/
SQL> SELECT * FROM tab2keyval(t, COLUMNS(A,B));
A B KEY_NAME KEY_VALUE
---------- ---------- ---------- --------------------
1 2
4 5
7 8
-- Now with exception handler
...
dbms_tf.row_replication(replication_factor => repfac);
dbms_tf.put_col(1, name_col);
dbms_tf.put_col(2, val_col);
EXCEPTION
when no_data_found then
raise_application_error(-20001,'NO_DATA_FOUND for Replication Factor!') ;
END;
END tab2keyval_pkg;
/
SQL> SELECT * FROM tab2keyval(t, COLUMNS(A,B));
ORA-20001: NO_DATA_FOUND for Replication Factor!
-- Re-raising NO_DATA_FOUND will be ignored
...
dbms_tf.row_replication(replication_factor => repfac);
dbms_tf.put_col(1, name_col);
dbms_tf.put_col(2, val_col);
EXCEPTION
when no_data_found then
raise;
END;
SQL> SELECT * FROM tab2keyval(t, COLUMNS(A,B));
A B KEY_NAME KEY_VALUE
---------- ---------- ---------- --------------------
1 2
4 5
7 8
Listing 3: NO_DATA_FOUND
We have caused an exception, but without an exception handler we got no error from the query: all new columns are just NULL. If we incorporate an exception handler, we can see that NO_DATA_FOUND was indeed raised and if we then raise our own exception, we’ll see it. On the other hand, re-raising NO_DATA_FOUND in exception handler will again actually hide an exception from query author.
Eliminate Rows
It’s easy, just set the replication factor to zero. Let’s say we wanted no even rows. The assignment on line 20 (Listing 4) will do that
...
PROCEDURE fetch_rows IS
rowset dbms_tf.row_set_t;
repfac dbms_tf.tab_naturaln_t;
rowcnt PLS_INTEGER;
colcnt PLS_INTEGER;
name_col dbms_tf.tab_varchar2_t;
val_col dbms_tf.tab_varchar2_t;
env dbms_tf.env_t := dbms_tf.get_env();
BEGIN
dbms_tf.get_row_set(rowset, rowcnt, colcnt);
FOR r IN 1..rowcnt LOOP
repfac(r) := 0;
FOR c IN 1..colcnt LOOP
repfac(r) := nvl(repfac(r),0) + 1;
name_col(nvl(name_col.last+1,1)) := INITCAP(regexp_replace(env.get_columns(c).name, '^"|"$'));
val_col(nvl(val_col.last+1,1)) := DBMS_TF.COL_TO_CHAR(rowset(c), r);
END LOOP;
IF mod(r,2)=0 THEN
repfac(r) := 0;
END IF;
END LOOP;
dbms_tf.row_replication(replication_factor => repfac);
dbms_tf.put_col(1, name_col);
dbms_tf.put_col(2, val_col);
EXCEPTION
when no_data_found then
raise;
END;
SQL> SELECT * FROM tab2keyval(t, COLUMNS(A,B));
A B KEY_NAME KEY_VALUE
---------- ---------- ---------- --------------------
1 2 C 3
1 2 V "ONE"
7 8 C 6
7 8 V "TWO"
Listing 4: Eliminate rows setting replication factor to zero
Insert rows
How about inserting rows? If you examine the package DBMS_TF, you can see that the record type DESCRIBE_T also has one another flag: row_insertion. But it is not mentioned in the documentation yet. I hope we will have a simple possibility to add rows in one of the next versions. Until then we only have the workaround with replication existing rows and then changing all needed columns. But think about the implication: since you cannot change the values of the PASS_THROUGH columns, you cannot use them, you have to make all columns FOR_READ, define the same columns as new and handle the whole assignments in FETCH_ROWS. Maybe I will show an example in one of the next posts in another context.
What we have seen and what’s next?
We learned how we can replicate and eliminate rows using row_replication procedure. We’ve also seen the special handling of NO_DATA_FOUND exception within a PTF (which can actually also be a bug). I think it’s time to start with table semantic PTF in the next post.
Hello Andrej,
Another excellent post 🙂
Unfortunately, the documentation of package DBMS_TF is very missing and also misleading.
For example, the DESCRIBE_T record has an incomplete description ( not including the row_replication
and row_insertion flags ) and, also, some of the data structures are not documented at all …
Luckily, you are here and willing to explain all the things, in a very clear and very instructive way :):)
Thanks a lot once again & Best Regards,
Iudith Mentzel
Hello Judith!
Thank you for your comment! You are right, there is room for improvement 😉
One example of a missing description is a type TABLE_COLUMNS_T, which is a type of a record field COLUMN of a table descriptor TABLE_T. You can guess that it is a table of column metadata by examining the examples or you can check the package DBMS_TF and find following:
/*---------------------------------------------------------------------- Type: TABLE_COLUMNS_T A collection of columns(COLUMN_T) */ TYPE TABLE_COLUMNS_T IS TABLE OF COLUMN_T;Best Regards
Andrej
Hi Andrej.
About swallowing of NO_DATA_FOUND exception, seems SQL engine swallows it from any user-defined pl/sql function called from an sql query.
Hi Yuri,
yes, you are right. But I think we have just different situation and this behavior is not applicable here. If the function is in select list, it’s okay.
But if we select from the function… Consider:
In this case we just got no data because of no_data_found exception. That’s logical, right?
But selecting from a PTF throwing no_data_found will return rows, just with nulls for generated columns.
How these erroneous NULLS can be distinguished from fully justified ones which the function can produce under certain circumstances?
I was trying to ask a question to Thomas Kyte about SQL Engine behaviour related to NO_DATA_FOUND, he said that it is just the way it works. Unfortunately Thomas’ blog is not public now, I cannot direct you to his answer.