

Last month I attended the DOAG conference in Nuremberg. As always, it was a great event, awesome community and excellent tech talks. And it seems that I’ve found what could be my favorite feature in the upcoming database release 18c. Keith Laker (@ASQLBarista), Oracle’s Product Manager for Analytic SQL, talked about “Building Agile Self-Describing SQL Functions For Big Data”. This title was promising enough for me and of course I wasn’t disappointed. Thanks a lot for an interesting presentation!
This blog post will be somewhat unusual, because I have actually no knowledge to share yet, but only the euphoria about the power and flexibility of the new feature. So what is it about?
You are most probably familiar with table functions. They can be pipelined or not, but that is not important at this time. The key property is that we can “select” from them in SQL like:
select * from table(dbms_xplan.display);
The second important property of the table functions is that they return a defined table data type. For example dbms_xplan.display returns the dbms_xplan_type_table, which is the table of VARCHAR2(4000). No way some logic inside the function dbms_xplan.display could change this returned data type to something else. This table type is fixed at design time. That’s the point. One could hardly provide generic extension functions.
But also the implementation of specific functions could be complicated. You can ask yourself, how to handle parallel execution? If you have been looking for a solution to aggregate (concatenate) strings before LISTAGG function has been introduced in 11g, you have probably seen Tom Kyte’s implementation of STRAGG function. Not really straightforward, using an object type with four methods, amongst others to merge partial result sets from execution in parallel.
Polymorphic Table Functions (PTF) address these problems. Being the part of ANSI SQL 2016 Polymorphic Table Functions are the evolution of the table functions. They can be invoked in the FROM clause. They accept data from any table, row type is not declared at design time. The function can process the input data adding or aggregating rows, adding or removing columns and so on and then return the enhanced row set to the SQL query. The row type of the result table also doesn’t need to be declared at design time.
I refrain from posting my own code as an example, because it would be a kind of speculation, never having tried it in a real system. Here is an example from Keith Laker’s presentation – returning credit score along with associated risk level:
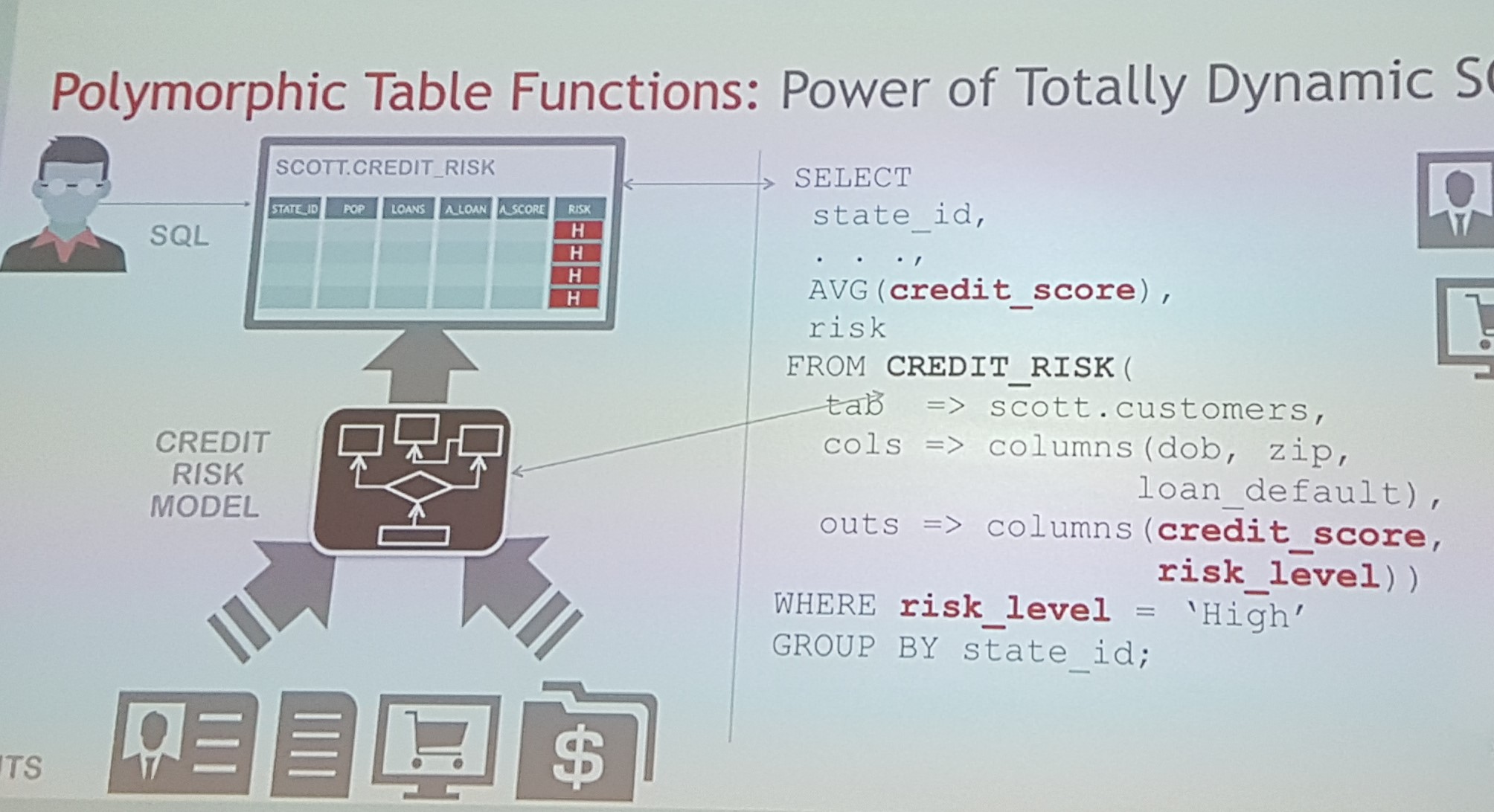
We are passing the table scott.customers into the function CREDIT_RISK, define the columns we need to accomplish the calculation and the columns we return. Actually, I think we also need to mention the column STATE_ID in the parameter OUTS to be able to “Group by” on it. But maybe I’m missing something. That’s it. We simply SELECT from this function and have two additional columns in the result set, which we use to aggregate and filter.
PTF can be distinguished in leaf and non-leaf and the latter can be row semantic (RS PTF) or table semantic (TS PTF). The difference is that with row semantic you can produce the output looking only at a single row. With table semantic you need also previously processed rows to produce the values for new columns or generate new rows – the kind of aggregate/analytic functions. With TS PTF you can optionally partition and order the input of the function like this:
SELECT *
FROM CUSTOM_GRPBY(scott.emp PARTITION BY job ORDER BY empno);
What about parallel processing? The statement is, the developer can simply assume a serial execution. Sounds great. Just one remark: in case of TS PTF you should provide a partitioning clause, like the prior example shows. All rows from a given partition end up in the same parallel slave. If you don’t provide partitioning key, the function creates a serialization point.
There are also some other good news for performance: bulk data transfer into and out of the PTF whereas only columns of interest are passed; if possible, the predicates, partitioning are pushed into underlying table.
All types and support routines to implement a PTF are in the package DBMS_TF. By the way, this package is already there in 12.2.0.1, but yet undocumented. You can even try to define your first PTF, but it doesn’t work. After all it is a 18c feature!
create or replace package ptf_test as
procedure describe (new_cols out dbms_tf.columns_new_t, tab in out dbms_tf.table_t, cols dbms_tf.columns_t) ;
function my_ptf (tab table, type_name varchar2, flip varchar2 default 'True') return table pipelined row polymorphic using ptf_test;
end;
/
show errors
LINE/COL ERROR
-------- --------------------------------------------------------
3/124 PLS-00998: implementation restriction (may be temporary)
What interesting use cases come to mind? Right now I’m working on integrating data in a data warehouse system which originaly came from XBRL format. Being persisted in the source database this XBRL-stuff looks like so hated called “key-value” tables. Now the requirements to process the huge key-value table are different and not “compatible”, mostly depending on keys. Sometimes you should aggregate them, sometimes pivot them, recognizing “tuples”, sometimes another stuff. This leads to multiple scans of the huge table. What if we had the possibility to scan the table just once and then conditionally group/aggregate, pivot, whatsoever? One could write an ETL process selecting from a huge table, maybe joined with other stuff, passing the data through PTF which prepares different kind of data and then directing the output with INSERT ALL into multiple target tables. All in just one step. If this also performs, why not?
Speaking of pivot, would it be also possible to provide a solution for dynamic PIVOT like the Anton Scheffer’s one , but without a need to pass the query text? Maybe I’m missing something, but it sounds good for me at the moment.
Should everything be working as described, and also be fast and scalable enough, it would be very interesting feature! Wait and see! Stay tuned, I will definitely write more about PTF next year and I can hardly wait to work on examples and slides for our New Features Training.
Pingback: Polymorphic Table Functions Example – Transposing Columns To Rows | SQLORA