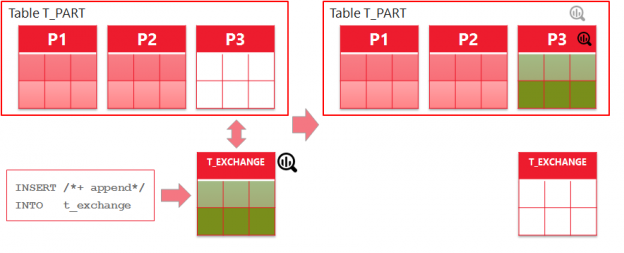
This is not just another post about why correct data types matter. Most of you know that using the wrong data type in WHERE or JOIN conditions can trigger implicit conversions, prevent an index access path, and cause performance problems. But what if you can’t change the SQL statements, and you don’t want to redesign your data model? This post is about possible solutions in case of a wrong cardinality estimation due to an implicit data type conversion.
Continue reading
Fix Optimizer Estimate Issues from Implicit Conversions #JoelKallmanDay
Leave a reply