
I have already posted some examples on Polymorphic Table Functions in Oracle 18c in the last months. I quickly realized how difficult it is to explain completely new feature using advanced examples and wanted to write a series of posts starting from very basics. Now that the Germany’s Oracle User Group (DOAG) has accepted my presentation on PTF for their annual conference is the time to do it.
Polymorphic Table Functions (abbreviated PTF) are the part of the SQL 2016 standard. Their definition can be summarized as follows:
- are user-defined table functions that can be called in FROM clause
- their row type is not declared when the function is created
- the row type of the result may depend on the function arguments and thus on precise invocation syntax
- PTF may have generic table parameters whose row type may not be declared at creation time (Caution! At least as of 18.0.1 Oracle requires exactly ONE table parameter)
There is a very useful and interesting publicly available document on PTF (ISO/IEC TR 19075-7:2017). Actually a “must read” one if you would like to have a deeper insight into the topic. But concerning Oracle’s implementation, be aware, not everything from the standard is implemented exactly in the described way or may not be implemented yet (as of 18.0.1). I’ll point out the differences as we go.
Motivation, Roles
With PTF it should be possible and simple to express sophisticated algorithms and encapsulate them within the DBMS making them generic and thus usable for various data sets just by invoking in a FROM clause of the SQL statement.
You could think about a PTF as a kind of view but more procedural and more dynamic. With views, there are three roles: query author, view author and DBMS. The view author is publishing an interface to the underlying tables without exposing the inner logic. The query author uses the view (published interface) in a query and the DBMS manages the execution. Similarly you’ll find the roles with a PTF:
- PTF author publishes an interface to a procedural mechanism that defines a result table. Responsible for the implementation of this mechanism
- query author uses the published interface by invoking the PTF in a query
- DBMS – is responsible for compilation, execution and state management
The query author doesn’t have to know or understand any technical implementation details, he just invokes the function in a SQL statement like he does with a view. But does the PTF author have to deal with all technical details? Only as far as these concern the actual business case, the business logic of the PTF. The really technical stuff like fetching rows, cursor management, parallel execution, etc. is delegated to the database and is hidden behind the clear interface provided by the package DBMS_TF.
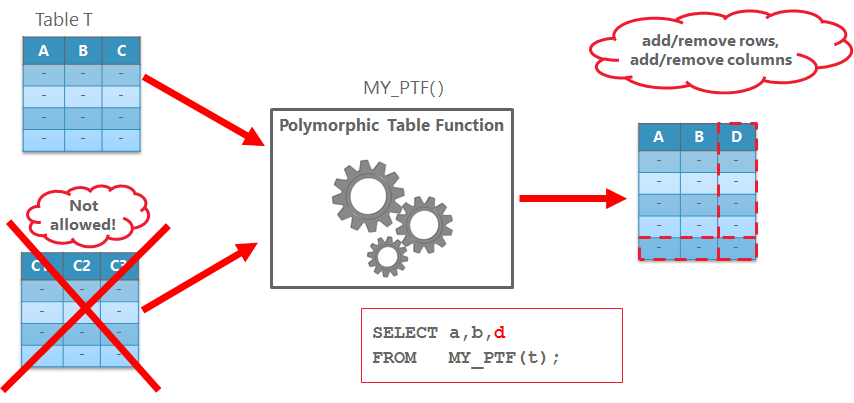
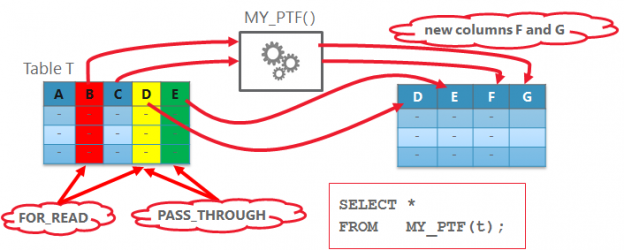
Figure 1: Basic PTF usage
PTF taxonomy
According to preview presentations from last year it should be possible to define a PTF without a table parameter at all. This should be called a leaf PTF. At the moment that kind of definition is neither possible nor mentioned in the documentation. Maybe it will be implemented in next releases. Now exactly one table parameter is required for PTF.
So we consider the non-leaf PTF’s only. They are further classified based on the semantic of the input table parameter:
- row semantic – the result of the function can be determined only by looking at the current row
- table semantic – the result of the function can be determined by looking at the current row and some state “summarized” from previously processed rows
Strictly speaking these properties are the properties of the input table parameters. As long as Oracle allows only for one input table, they can also be used to classify the functions themselves, but if this restriction will eventually be lifted, this won’t be possible anymore. SQL standard allows for multiple generic input table parameters having their own semantic.
The row semantic PTF’s are sufficient for example if you need:
- to add some derived columns with really complicated calculations behind them (otherwise you’d be probably better off with a view or virtual column)
- to reformat the row: splitting it, renaming, hiding, manipulating columns, etc.
- to replicate the rows
- to output rows in defined format, e.g. JSON, XML
- to pivot the columns
- etc.
The table semantics PTF’s are useful to implement user-defined analytics like aggregation or window functions. They operate on an entire table or a logical partition of it.
Definition, Invocation
Let’s start with a basic example: refer to the Figure 1, we should implement a PTF which accepts any table, a list of columns to discard and produces a new column with the name and value specified by invocation. Please don’t ask me for the sense and don’t contradict, this could be achieved much simpler just with a view – it is for demonstration purpose only. 😉
The table we will use is defined as follows
CREATE TABLE t (A NUMBER, B NUMBER, C NUMBER);
INSERT INTO t VALUES (1,2,3);
INSERT INTO t VALUES (4,5,6);
INSERT INTO t VALUES (7,8,9);
COMMIT;
Listing 1: Test table
What do you need to define a PTF? First, you need an implementation package, where you have to define the functions for the key PTF interfaces. You can then define the PTF itself within the package or as a standalone function at schema level.
CREATE OR REPLACE PACKAGE my_ptf_package
AS
FUNCTION my_ptf (tab TABLE
, cols_to_discard COLUMNS DEFAULT NULL
, new_col_name VARCHAR2 DEFAULT NULL
, new_col_val VARCHAR2 DEFAULT NULL)
RETURN TABLE PIPELINED ROW POLYMORPHIC USING my_ptf_package;
END my_ptf_package;
/
Listing 2: PTF defined as a package function
The first parameter tab of type TABLE is required for every PTF. Except for it we defined another three parameters: for the column list to discard, for the name of the new column and the value of it. I’ve made them optional to demonstrate the absolutely minimalistic version of our PTF (see later). Of course it’s just a matter of your business case – all parameters can be made required.
We then specify the return type which is simply TABLE. Yes, we don’t have to declare and specify any user-defined types and this is one of the main goals and advantages of polymorphic table functions. Well, our PTF is PIPELINED, but it’s nothing new to this clause. Then we specify the functions semantic. We can accomplish our simple task by looking at just one row, so the semantic will be ROW. The clause POLYMORPHIC tells the function is a PTF and finally we tell the database where to find the implementation methods – USING my_ptf_package.
If we wanted to hide the column C and introduce the new column D with the value “Hello world!”, the invocation would look something like this:
-- Package-qualified
SELECT *
FROM my_ptf_package.my_ptf(t, COLUMNS(C), 'D', 'Hello world!');
Listing 3: Calling PTF in SQL
Look at the second parameter – we are using the new pseudo-operator COLUMNS here. It has been introduced in 18c to support Polymorphic Table Functions. See Variadic Pseudo-Operators for more details. It is used to pass a list of columns as a parameter into a PTF. There can be multiple parameters of this type with the meaning you define as PTF author.
All supporting types and routines you need to implement a PTF are in the package DBMS_TF. Besides the package documentation you can have a look into the package specification itself and find valuable comments.
Next we have to define the interface methods/functions. There are four of the PTF interface methods: DESCRIBE, OPEN, FETCH_ROWS and CLOSE. Only DESCRIBE is required. Why?
Compilation and execution
Look at the Figure 1. How does the database know about the column D? It looks like magic and behaves somehow like dynamic SQL, but it is not! Well, it’s no magic here. You (PTF author) tell it! The SQL statement which invokes a PTF will be parsed just like any other and at this moment your defined DESCRIBE method will be called. It is the function where you tell the database how the result rows of your function will look like.
What parameters must be specified for the DECSRIBE function? Generally speaking, they are the same as for the PTF itself, with the difference that the parameters of type TABLE and COLUMNS are converted to according record resp. table PL/SQL types defined in DBMS_TF. Scalar parameters, if any, remain the same. The DESCRIBE function requieres exactly one parameter of type dbms_tf.table_t which describes the input table. The DBMS is responsible for filling the record type and passing it to DESCRIBE during the statement parsing. This parameter is declared as IN OUT because you not only get the information about the table columns, but it is also the way to tell the database what you intend to do with those columns – more on this later. Also the the parameter of type COLUMNS will be converted to the PL/SQL table type dbms_tf.columns_t.
The return type of the function DESCRIBE is the record type DESCRIBE_T, which is basically used to inform the database about new columns via collection (COLUMNS_NEW_T) of records COLUMN_METADATA_T. Other usages – compilation state and method names – will be described in following posts.
Let’s code. Specify all four parameters doing the described type substitution. In the package body we’ll first do nothing in the DESCRIBE function (return NULL).
CREATE OR REPLACE PACKAGE my_ptf_package AS
FUNCTION my_ptf (tab TABLE
, cols_to_discard COLUMNS DEFAULT NULL
, new_col_name VARCHAR2 DEFAULT NULL
, new_col_val VARCHAR2 DEFAULT NULL)
RETURN TABLE PIPELINED ROW POLYMORPHIC USING my_ptf_package;
FUNCTION describe(
tab IN OUT dbms_tf.table_t,
cols_to_discard IN dbms_tf.columns_t DEFAULT NULL,
new_col_name VARCHAR2 DEFAULT NULL,
new_col_val VARCHAR2 DEFAULT NULL)
RETURN dbms_tf.describe_t;
END my_ptf_package;
/
CREATE OR REPLACE PACKAGE BODY my_ptf_package AS
FUNCTION describe(
tab IN OUT dbms_tf.table_t,
cols_to_discard IN dbms_tf.columns_t DEFAULT NULL,
new_col_name VARCHAR2 DEFAULT NULL,
new_col_val VARCHAR2 DEFAULT NULL)
RETURN dbms_tf.describe_t IS
BEGIN
RETURN NULL;
END;
END my_ptf_package;
/
set echo on
SQL> SELECT * FROM my_ptf_package.my_ptf(t);
A B C
---------- ---------- ----------
1 2 3
4 5 6
7 8 9
Listing 4: Describe-only PTF
At least, we could compile the package without an error. Note, that we don’t need to provide any implementation of the PTF in the package body. But what happens, if we try to invoke the function in some SQL statement? It works! Well, it does nothing meaningful, simply passing all data through “as is”. Except for the three optional parameters we introduced to support intended functionality, we just created the smallest and simplest PTF you can write.
How does it work? First, we told the database there are no new columns to expect by returning NULL as a result of DESCRIBE. The fact that existing columns where passed through is due to special column properties/flags in the column descriptor:
TYPE column_t IS RECORD (
description COLUMN_METADATA_T,
pass_through BOOLEAN,
for_read BOOLEAN);
Listing 5: Column descriptor type
Pass-through columns are passed to the output without any modifications. Read columns (for_read is TRUE) are those that will be processed during the execution inside FETCH_ROWS. These flags are not mutually exclusive. To understand the interaction, look at Figure 2.
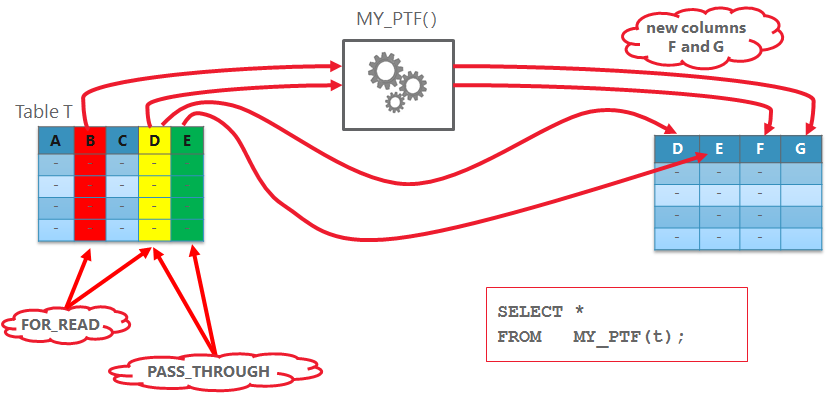
Figure 2: Pass-through and read columns
Suppose the DESCRIBE function has marked the column B as “for read” (red) and the column E as pass-through (green). The column D is both for read and pass-through (yellow – R+G=Y 😉 ). During the execution columns D and E automatically become part of the result row. Additionally there are any new columns (F and G) which DESCRIBE method has declared. Columns B and D (for read) are passed to the function and are the only columns you will see and can evaluate during the execution. Important notice: you cannot change any existing column values! You can either pass through “as is” or define a new column and assign a modified value to it.
Now, the documentation states, all columns in the Row Semantics PTF are marked as pass-through by default. That’s why in former example the function has worked without any implementation. But we actually wanted to discard some columns and introduce a new one. Let’s do it!
Let’s first take care of discarding the columns. We only need to iterate through table columns and check whether the column is in discard list. If so, mark it as not pass-through. Still return NULL, no new columns yet.
CREATE OR REPLACE PACKAGE BODY my_ptf_package AS
FUNCTION describe(
tab IN OUT dbms_tf.table_t,
cols_to_discard IN dbms_tf.columns_t DEFAULT NULL,
new_col_name VARCHAR2 DEFAULT NULL,
new_col_val VARCHAR2 DEFAULT NULL)
RETURN dbms_tf.describe_t IS
BEGIN
-- we need to find columns to discard
-- all other will be passed through by default
FOR I IN 1 .. tab.COLUMN.COUNT LOOP
IF tab.COLUMN(i).description.name MEMBER OF cols_to_discard THEN
tab.column(i).pass_through := false;
END IF;
END LOOP;
RETURN NULL;
END;
END my_ptf_package;
/
SQL> SELECT * FROM my_ptf_package.my_ptf(t, COLUMNS(C));
A B
---------- ----------
1 2
4 5
7 8
SQL> SELECT * FROM my_ptf_package.my_ptf(t, COLUMNS(B,C));
A
----------
1
4
7
Listing 6: The next version our PTF discarding specified columns
Works as expected. Now let us introduce the new column. The name of the column is known (passed as a parameter) and the data type is actually hard coded as VARCHAR2. If you wonder about this syntax (1 => dbms_tf… just read about qualified expressions in 18c
CREATE OR REPLACE PACKAGE BODY my_ptf_package AS
FUNCTION describe(
tab IN OUT dbms_tf.table_t,
cols_to_discard IN dbms_tf.columns_t DEFAULT NULL,
new_col_name VARCHAR2 DEFAULT NULL,
new_col_val VARCHAR2 DEFAULT NULL)
RETURN dbms_tf.describe_t IS
BEGIN
-- we need to find columns to discard
-- all other will be passed through by default
FOR I IN 1 .. tab.COLUMN.COUNT LOOP
IF tab.COLUMN(i).description.name MEMBER OF cols_to_discard THEN
tab.column(i).pass_through := false;
END IF;
END LOOP;
RETURN dbms_tf.describe_t(
new_columns =>
dbms_tf.columns_new_t(
1 => dbms_tf.column_metadata_t(
name => new_col_name,
TYPE => dbms_tf.type_varchar2)));
END;
END my_ptf_package;
/
SQL> SELECT * FROM my_ptf_package.my_ptf(t, COLUMNS(C), 'D');
ORA-62573: new column (D) is not allowed with describe only
polymorphic table function
Listing 7: Trying to introduce new columns without FETCH_ROWS implementation: ORA-62573
What’s going on? Well, until now we only have defined a DESCRIBE function. Our PTF has worked but it was what is called “describe-only” PTF. No new columns are permitted for such PTF. Our code was executed only once during statement parsing (compilation). In order to introduce new columns, we need to define what has to happen with them during the execution. We need to define other methods, FETCH_ROWS in first place.
Execution
What parameters does the procedure FETCH_ROWS need? Any scalar parameters defined for the PTF itself, i.e. not of type TABLE or COLUMNS, are also required for FETCH_ROWS. Otherwise you’ll get the same ORA-62573 error. Why so? Because of the signature mismatch the database does not recognize the FETCH_ROWS as an implementation method for our PTF. It looks just like some other procedure in the package, nothing to do with a PTF.
CREATE OR REPLACE PACKAGE my_ptf_package AS
FUNCTION my_ptf (tab TABLE
, cols_to_discard COLUMNS DEFAULT NULL
, new_col_name VARCHAR2 DEFAULT NULL
, new_col_val VARCHAR2 DEFAULT NULL)
RETURN TABLE PIPELINED ROW POLYMORPHIC USING my_ptf_package;
FUNCTION describe(
tab IN OUT dbms_tf.table_t,
cols_to_discard IN dbms_tf.columns_t DEFAULT NULL,
new_col_name VARCHAR2 DEFAULT NULL,
new_col_val VARCHAR2 DEFAULT NULL)
RETURN dbms_tf.describe_t;
PROCEDURE fetch_rows (new_col_name VARCHAR2 DEFAULT NULL,
new_col_val VARCHAR2 DEFAULT NULL);
END my_ptf_package;
/
CREATE OR REPLACE PACKAGE BODY my_ptf_package AS
FUNCTION describe(
tab IN OUT dbms_tf.table_t,
cols_to_discard IN dbms_tf.columns_t DEFAULT NULL,
new_col_name VARCHAR2 DEFAULT NULL,
new_col_val VARCHAR2 DEFAULT NULL)
RETURN dbms_tf.describe_t IS
BEGIN
-- we need to find columns to discard
-- all other will be passed through by default
FOR I IN 1 .. tab.COLUMN.COUNT LOOP
IF tab.COLUMN(i).description.name MEMBER OF cols_to_discard THEN
tab.column(i).pass_through := false;
END IF;
END LOOP;
RETURN dbms_tf.describe_t(
new_columns =>
dbms_tf.columns_new_t(
1 => dbms_tf.column_metadata_t(
name => new_col_name,
TYPE => dbms_tf.type_varchar2)));
END;
PROCEDURE fetch_rows (new_col_name VARCHAR2 DEFAULT NULL,
new_col_val VARCHAR2 DEFAULT NULL) IS
valcol dbms_tf.tab_varchar2_t;
env dbms_tf.env_t := dbms_tf.get_env();
BEGIN
-- For all rows just assign a constant value
FOR i IN 1..env.row_count LOOP
valcol(nvl(valcol.last+1,1)) := new_col_val;
END LOOP;
-- Put the collection with values back
DBMS_TF.PUT_COL(1, valcol);
END;
END my_ptf_package;
/
SQL> SELECT * FROM my_ptf_package.my_ptf(t, COLUMNS(C),
'D', 'Hello World!');
A B D
---------- ---------- ------------
1 2 Hello World!
4 5 Hello World!
7 8 Hello World!
Listing 8: Works! Discard columns and introduce a new one
Mission completed. The implementation of FETCH_ROWS looks not that complex. What happens there? We don’t need to evaluate any columns for our simple task, just assign a constant value to a new column. Sounds easy, but how? Only once or for each input row? If for each row, how many are there, anyway? Will FETCH_ROWS be executed only once seeing all rows or multiple times? Do I even know? Do I need to know? The answer to the most questions is as always, it depends… But again, the implementation of the polymorphic table functions has the goal that the PTF author does not have to worry about it. In general FETCH_ROWS can be called multiple times. You don’t know and don’t need to know how often it will be called. You operate only on the current (active) row set. How big is this row set? We can see this in ENV_T, the record type containing the information about current execution state, which is filled by calling dbms_tf.get_env(). Another way could be an out parameter from fetching the rows with procedures dbms_tf.get_row_set or dbms_tf.get_column, but we didn’t use them since we dont’t need to fetch any read columns to fulfill our task. The examples for these procedures will follow in the next posts.
How are the values for columns stored during the execution of FETCH_ROWS? First, DBMS_TF supports fifteen scalar data types that can only be used for read columns. There is a table type ROW_SET_T which is a table of records of the type COLUMN_DATA_T. Which in turn has a DESCRIPTION (record type COLUMN_METADATA_T) and fifteen so called variant fields for all supported types. These variant fields are actually collections (associative arrays or index-by tables in terms of PL/SQL). Only one variant field of the proper data type is active for one column. Refer to Figure 3
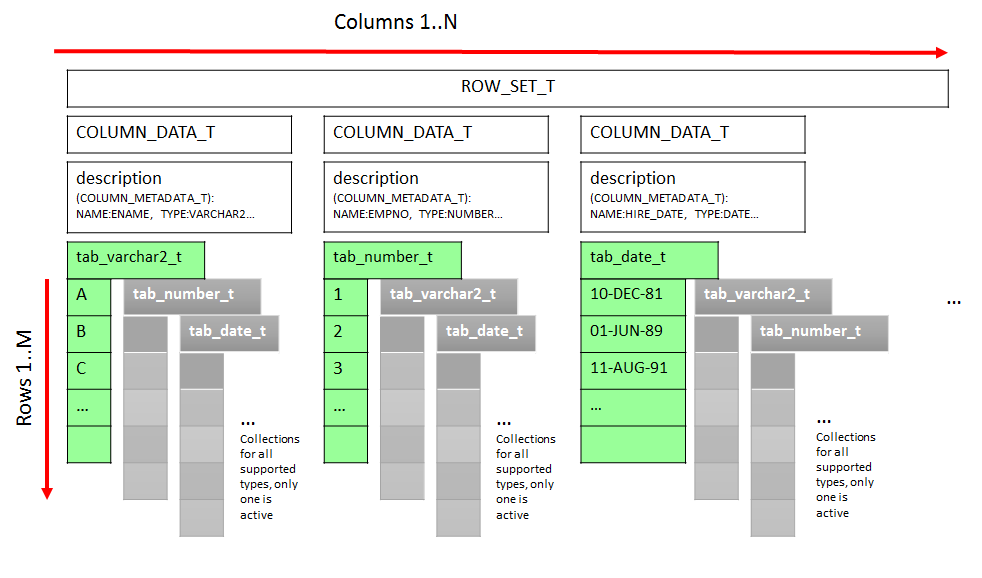
Figure 3 Storing input and output values in the collections of DBMS_TF
We use the overloaded procedure dbms_tf.put_col which expect the collection of one of the fifteen defined types. This collection is holding the values for each row.
What’s next?
We introduced the new column but didn’t really used any input data flowing into the function. In the next post we continue to look at the basics and show how we can do it.
Hello Andrej,
Sorry for my late reply.
You deserve a HUGE THANKS for one of the best articles that I read in a long time 🙂 🙂 🙂
You have an amazing talent to explain things clearly, so I am eagerly waiting for your following posts.
This will be for sure THE BEST documentation available for the topic and I will make my best
to make in known to as many developers as possible.
Thank you lots of times in advance & Best Regards,
Iudith Mentzel
Oracle developer
Hello Iudith,
Thank you for your motivating comments! The second part is there, the third and fourth in planning 😉
Best Regards
Andrej
I am afraid, the code “Listing 8: Works! Discard columns and introduce a new one” is not working .
Error :ORA-62561: Invalid column ID (0) in Get_Col or Put_Col
Hi,
what exactly are you doing? Can you please post it? Here is my output:
SQL> set echo on SQL> SQL> CREATE TABLE t (A NUMBER, B NUMBER, C NUMBER); Table T created. SQL> SQL> INSERT INTO t VALUES (1,2,3); 1 row inserted. SQL> INSERT INTO t VALUES (4,5,6); 1 row inserted. SQL> INSERT INTO t VALUES (7,8,9); 1 row inserted. SQL> SQL> COMMIT; Commit complete. SQL> SQL> CREATE OR REPLACE PACKAGE my_ptf_package AS 2 3 FUNCTION my_ptf (tab TABLE 4 , cols_to_discard COLUMNS DEFAULT NULL 5 , new_col_name VARCHAR2 DEFAULT NULL 6 , new_col_val VARCHAR2 DEFAULT NULL) 7 RETURN TABLE PIPELINED ROW POLYMORPHIC USING my_ptf_package; 8 9 FUNCTION describe( 10 tab IN OUT dbms_tf.table_t, 11 cols_to_discard IN dbms_tf.columns_t DEFAULT NULL, 12 new_col_name VARCHAR2 DEFAULT NULL, 13 new_col_val VARCHAR2 DEFAULT NULL) 14 RETURN dbms_tf.describe_t; 15 16 PROCEDURE fetch_rows (new_col_name VARCHAR2 DEFAULT NULL, 17 new_col_val VARCHAR2 DEFAULT NULL); 18 END my_ptf_package; 19 / Package MY_PTF_PACKAGE compiled SQL> SQL> CREATE OR REPLACE PACKAGE BODY my_ptf_package AS 2 3 FUNCTION describe( 4 tab IN OUT dbms_tf.table_t, 5 cols_to_discard IN dbms_tf.columns_t DEFAULT NULL, 6 new_col_name VARCHAR2 DEFAULT NULL, 7 new_col_val VARCHAR2 DEFAULT NULL) 8 RETURN dbms_tf.describe_t IS 9 BEGIN 10 -- we need to find columns to discard 11 -- all other will be passed through by default 12 FOR I IN 1 .. tab.COLUMN.COUNT LOOP 13 IF tab.COLUMN(i).description.name MEMBER OF cols_to_discard THEN 14 tab.column(i).pass_through := false; 15 END IF; 16 END LOOP; 17 18 RETURN dbms_tf.describe_t( 19 new_columns => 20 dbms_tf.columns_new_t( 21 1 => dbms_tf.column_metadata_t( 22 name => new_col_name, 23 TYPE => dbms_tf.type_varchar2))); 24 END; 25 26 27 PROCEDURE fetch_rows (new_col_name VARCHAR2 DEFAULT NULL, 28 new_col_val VARCHAR2 DEFAULT NULL) IS 29 valcol dbms_tf.tab_varchar2_t; 30 env dbms_tf.env_t := dbms_tf.get_env(); 31 BEGIN 32 -- For all rows just assign a constant value 33 FOR i IN 1..env.row_count LOOP 34 valcol(nvl(valcol.last+1,1)) := new_col_val; 35 END LOOP; 36 -- Put the collection with values back 37 DBMS_TF.PUT_COL(1, valcol); 38 END; 39 40 END my_ptf_package; 41 / Package Body MY_PTF_PACKAGE compiled SQL> SQL> column d format a20 SQL> SQL> SELECT * FROM my_ptf_package.my_ptf(t, COLUMNS(C), 'D', 'Hello World!'); A B D ---------- ---------- -------------------- 1 2 Hello World! 4 5 Hello World! 7 8 Hello World!I really like the way you explain PTF. Thank you.
Thank you, Chan! Glad to hear, the time and effort are not wasted
This does not seem to work on 19c anymore and results in
ERROR at line 2:
ORA-62566: One of the new column names is a zero-length identifier.
In fact, the values passed as (scalar) parameters to describes are always NULL within describe.
Hello René,
what exactly did you test and on what version? Here is my output from 19.2 and 19.8. It is still working for me.
SQL> SELECT banner_full FROM V$VERSION; BANNER_FULL ---------------------------------------------------------------------------------------------------------------------------------------------------------------- Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.8.0.0.0 SQL> SQL> CREATE OR REPLACE PACKAGE my_ptf_package AS 2 3 FUNCTION my_ptf (tab TABLE 4 , cols_to_discard COLUMNS DEFAULT NULL 5 , new_col_name VARCHAR2 DEFAULT NULL 6 , new_col_val VARCHAR2 DEFAULT NULL) 7 RETURN TABLE PIPELINED ROW POLYMORPHIC USING my_ptf_package; 8 9 FUNCTION describe( tab IN OUT dbms_tf.table_t, 10 cols_to_discard IN dbms_tf.columns_t DEFAULT NULL, 11 new_col_name VARCHAR2 DEFAULT NULL, 12 new_col_val VARCHAR2 DEFAULT NULL) 13 RETURN dbms_tf.describe_t; 14 15 PROCEDURE fetch_rows (new_col_name VARCHAR2 DEFAULT NULL, 16 new_col_val VARCHAR2 DEFAULT NULL); 17 END my_ptf_package; 18 / Package MY_PTF_PACKAGE compiled SQL> SQL> CREATE OR REPLACE PACKAGE BODY my_ptf_package AS 2 3 FUNCTION describe( 4 tab IN OUT dbms_tf.table_t, 5 cols_to_discard IN dbms_tf.columns_t DEFAULT NULL, 6 new_col_name VARCHAR2 DEFAULT NULL, 7 new_col_val VARCHAR2 DEFAULT NULL) 8 RETURN dbms_tf.describe_t IS 9 BEGIN 10 -- we need to find columns to discard 11 -- all other will be passed through by default 12 FOR I IN 1 .. tab.COLUMN.COUNT LOOP 13 IF tab.COLUMN(i).description.name MEMBER OF cols_to_discard THEN 14 tab.column(i).pass_through := false; 15 END IF; 16 END LOOP; 17 18 RETURN dbms_tf.describe_t( 19 new_columns => 20 dbms_tf.columns_new_t( 21 1 => dbms_tf.column_metadata_t( 22 name => new_col_name, 23 TYPE => dbms_tf.type_varchar2))); 24 END; 25 26 27 PROCEDURE fetch_rows (new_col_name VARCHAR2 DEFAULT NULL, 28 new_col_val VARCHAR2 DEFAULT NULL) IS 29 valcol dbms_tf.tab_varchar2_t; 30 env dbms_tf.env_t := dbms_tf.get_env(); 31 BEGIN 32 -- For all rows just assign a constant value 33 FOR i IN 1..env.row_count LOOP 34 valcol(nvl(valcol.last+1,1)) := new_col_val; 35 END LOOP; 36 -- Put the collection with values back 37 DBMS_TF.PUT_COL(1, valcol); 38 END; 39 40 END my_ptf_package; 41 / Package Body MY_PTF_PACKAGE compiled SQL> SQL> SQL> SELECT * FROM my_ptf_package.my_ptf(t, COLUMNS(C), 'D', 'Hello World!'); A B D ---------- ---------- ------------ 1 2 Hello World! 4 5 Hello World! 7 8 Hello World!SQL> SELECT banner_full FROM V$VERSION; BANNER_FULL ---------------------------------------------------------------------------------------------------------------------------------------------------------------- Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.2.0.0.0 SQL> SQL> CREATE OR REPLACE PACKAGE my_ptf_package AS 2 3 FUNCTION my_ptf (tab TABLE 4 , cols_to_discard COLUMNS DEFAULT NULL 5 , new_col_name VARCHAR2 DEFAULT NULL 6 , new_col_val VARCHAR2 DEFAULT NULL) 7 RETURN TABLE PIPELINED ROW POLYMORPHIC USING my_ptf_package; 8 9 FUNCTION describe( tab IN OUT dbms_tf.table_t, 10 cols_to_discard IN dbms_tf.columns_t DEFAULT NULL, 11 new_col_name VARCHAR2 DEFAULT NULL, 12 new_col_val VARCHAR2 DEFAULT NULL) 13 RETURN dbms_tf.describe_t; 14 15 PROCEDURE fetch_rows (new_col_name VARCHAR2 DEFAULT NULL, 16 new_col_val VARCHAR2 DEFAULT NULL); 17 END my_ptf_package; 18 / Package MY_PTF_PACKAGE compiled SQL> SQL> CREATE OR REPLACE PACKAGE BODY my_ptf_package AS 2 3 FUNCTION describe( 4 tab IN OUT dbms_tf.table_t, 5 cols_to_discard IN dbms_tf.columns_t DEFAULT NULL, 6 new_col_name VARCHAR2 DEFAULT NULL, 7 new_col_val VARCHAR2 DEFAULT NULL) 8 RETURN dbms_tf.describe_t IS 9 BEGIN 10 -- we need to find columns to discard 11 -- all other will be passed through by default 12 FOR I IN 1 .. tab.COLUMN.COUNT LOOP 13 IF tab.COLUMN(i).description.name MEMBER OF cols_to_discard THEN 14 tab.column(i).pass_through := false; 15 END IF; 16 END LOOP; 17 18 RETURN dbms_tf.describe_t( 19 new_columns => 20 dbms_tf.columns_new_t( 21 1 => dbms_tf.column_metadata_t( 22 name => new_col_name, 23 TYPE => dbms_tf.type_varchar2))); 24 END; 25 26 27 PROCEDURE fetch_rows (new_col_name VARCHAR2 DEFAULT NULL, 28 new_col_val VARCHAR2 DEFAULT NULL) IS 29 valcol dbms_tf.tab_varchar2_t; 30 env dbms_tf.env_t := dbms_tf.get_env(); 31 BEGIN 32 -- For all rows just assign a constant value 33 FOR i IN 1..env.row_count LOOP 34 valcol(nvl(valcol.last+1,1)) := new_col_val; 35 END LOOP; 36 -- Put the collection with values back 37 DBMS_TF.PUT_COL(1, valcol); 38 END; 39 40 END my_ptf_package; 41 / Package Body MY_PTF_PACKAGE compiled SQL> SQL> SQL> SELECT * FROM my_ptf_package.my_ptf(t, COLUMNS(C), 'D', 'Hello World!'); A B D ---------- ---------- ------------ 1 2 Hello World! 4 5 Hello World! 7 8 Hello World!