

A few days ago I received a comment/question on the older post about dynamically transposing rows to column with Polymorphic Table Functions (PTF). Back then I overlooked a bug in the example code, but the explanation takes a bit longer, so i decided to write a new post about it. The PTF was working initially but after inserting new data started to return wrong results – all NULL’s for some columns where we know there are actually values present. So, what’s going on?
For Rafal, who asked the question, the result is looking like this:
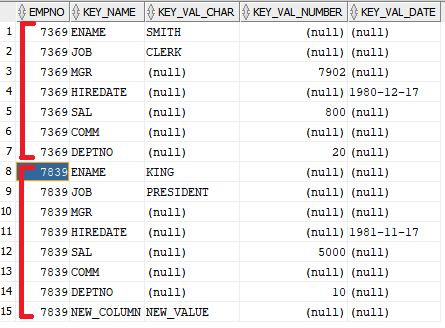
SQL> INSERT INTO t (empno, key_name, key_val_char) VALUES(7839, 'NEW_COLUMN', 'NEW_VALUE');
1 row inserted.
SQL> SELECT * FROM keyval2tab(t PARTITION BY empno,'T');
EMPNO DEPTNO SAL HIREDATE NEW_COLUMN COMM JOB MGR ENAME
________ _________ _______ ___________ _____________ _______ ____________ ______ ________
7369 20 800 80/12/17
7499 30 1600 81/02/20
7521 30 1250 81/02/22
7566 20 2975 81/04/02
7654 30 1250 81/09/28
7698 30 2850 81/05/01
7782 10 2450 81/06/09
7788 20 3000 87/04/19
7839 10 5000 81/11/17 NEW_VALUE PRESIDENT KING
7844 30 1500 81/09/08
7876 20 1100 87/05/23
7900 30 950 81/12/03
7902 20 3000 81/12/03
7934 10 1300 82/01/23
14 rows selected.
Listing 1
All columns after HIREDATE are NULL in all rows except of the row where the value for the NEW_COLUMN is present. Before we look at the code of the PTF to find the reason, let’s look at two important points.
How SQL handles NO_DATA_FOUND
Consider following example:
SQL> create or replace function my_pipeline return sys.odcivarchar2list pipelined is
2 begin
3 for i in 1..5 loop
4 if i = 3 then
5 raise no_data_found;
6 end if;
7 pipe row (i);
8 end loop;
9 end;
10 /
Function MY_PIPELINE compiled
SQL>
SQL>
SQL> select column_value from my_pipeline();
COLUM
-----
1
2
Listing 2
Although we throw an exception in the function, we do not get an error at the SQL level. The processing stops there, but, nevertheless, we get the first two rows. This behavior is not unexpected and is described for example in this thread on AksTom.
I go along with that, but the next example is less easy for me to follow (but that is how it is 🙂 )
SQL> create or replace function my_lower (p_str varchar2) return varchar2 is
2 begin
3 raise no_data_found;
4 return lower (p_str);
5 end;
6 /
Function MY_LOWER compiled
SQL>
SQL>
SQL> select dummy
2 , my_lower(dummy) lower_dummy
3 from dual;
D LOWER_DUMMY
- -----------
X
Listing 3
If we want to return a PL/SQL function result in a SQL and the function throws uncaught NO_DATA_FOUND exception then we will still get all rows but the corresponding columns will be NULL! This can for example happen when using recursive SQL inside a function or this can just as well happen when referencing non-existent associative array elements!
Referencing non-existent associative array elements
Associative arrays (or INDEX BY tables) in PL/SQL are sparse. They can have gaps, but referencing a non-existent element throws a NO_DATA_FOUND exception:
declare
type t_tab is table of number index by pls_integer;
v_tab t_tab;
begin
v_tab(1) := 1;
v_tab(3) := 3;
dbms_output.put_line(v_tab(1)||v_tab(2)||v_tab(3));
end;
Error report -
ORA-01403: no data found
ORA-06512: at line 7
Listing 4
Skipping the second element and assigning the third one was okay, but referencing the unassigned second element in line 7 throws an exception.
What does it mean for PTF’s?
Looking at the package DBMS_TF we will see that most of the collections we have to use are declared as associative arrays:
/* Collections for each supported types */
TYPE TAB_VARCHAR2_T IS TABLE OF VARCHAR2(32767) INDEX BY PLS_INTEGER;
TYPE TAB_NUMBER_T IS TABLE OF NUMBER INDEX BY PLS_INTEGER;
TYPE TAB_DATE_T IS TABLE OF DATE INDEX BY PLS_INTEGER;
...
Listing 5
We have to be careful not to access a non-existent element ourselves, but just as important not to hand over such sparse collections for further processing to the database.
Let’s now look at the code of the PTF from the initial post to see what I mean. What we are doing here is trying to transpose the rows with key names and key values back to the table structure. After we inserted one more key/value pair for EMPNO=7839, we have 8 key for this EMPNO but still 7 keys for all others. It shouldn’t be a problem though. The DESCRIBE method will have to look into the data (that is the price we pay for being “dynamic”), gather all possible keys and therefore define that there will be 8 columns in the result set. So far so good.
Then we start processing and that is where our FETCH_ROWS method will be called. We are calling the PTF using PARTITION BY EMPNO – it have to be that because we are gathering key/values for a particular EMPNO. That means that FETCH_ROWS will be called once for each EMPNO.
What happens with EMPNO’s which don’t have this additional key NEW_COLUMN? The problem is in the procedure FETCH_ROWS. See the excerpt of the listing 8 from the initial post (lines 110 to 125):
FOR r IN 1 .. rowcnt LOOP
FOR p IN 1 .. env.put_columns.count LOOP
IF inp_rs(idcol_cnt+1).tab_varchar2(r)=replace(env.put_columns(p).name,'"') THEN
IF env.put_columns(p).type = dbms_tf.type_varchar2 then
out_rs(p).tab_varchar2(1):= inp_rs(idcol_cnt+2).tab_varchar2(r);
ELSIF env.put_columns(p).type = dbms_tf.type_number then
out_rs(p).tab_number(1):= inp_rs(idcol_cnt+3).tab_number(r);
ELSIF env.put_columns(p).type = dbms_tf.type_date then
out_rs(p).tab_date(1):= inp_rs(idcol_cnt+4).tab_date(r);
END IF;
END IF;
END LOOP;
END LOOP;
dbms_tf.put_row_set (out_rs, repfac);
END;
Listing 6
You don’t need to fully understand what these variables, arrays, etc. are meaning. I’ll explain the problem. We are constructing the output rowset OUT_RS and then hand it over to the procedure DBMS_TF.PUT_ROW_SET.
We are iterating from 1 to 7 in the outer loop – the rows from one partition of the queried table (EMPNO=7369). On the other hand the inner loop will iterate over 9 (8 known keys plus EMPNO) columns in the output result set. It will find and provide values for seven of them but not for the column NEW_COLUMN which is not known for this EMPNO. We end up with the structure of OUT_RS like this

Look at the difference between element five and six: for the column COMM we know the value is NULL but for the column NEW_COLUMN there is no element in the array TAB_VARCHAR2_T at all. Obviously, the procedure DBMS_TF.PUT_ROW_SET is iterating the OUT_RS and after processing first four columns NO_DATA_FOUND exception is thrown. The columns five to nine will not be processed for this output row anymore. That is the reason we see all NULL’s for the columns after HIREDATE. But as we can assume from what we have seen in listings 2 and 3 at the beginning of this post: the processing doesn’t stop there, the next row will be processed which unfortunately will have the same problem and so on, until we reach the EMPNO = 7839. For this row we will be able to output all columns correctly.
Quite bad: we are returning wrong results and don’t even know about it.
How can we prove what is happening?
Just add an exception handler to FETCH_ROWS, catch NO_DATA_FOUND and throw another exception instead of it:
...
dbms_tf.put_row_set (out_rs, repfac);
EXCEPTION
when no_data_found then
raise_application_error(-20001,'NO_DATA_FOUND! '||chr(13)||dbms_utility.format_error_backtrace) ;
END;
SQL> SELECT * FROM keyval2tab(t PARTITION BY empno,'T');
ORA-20001: NO_DATA_FOUND!
ORA-06512: at "SYS.DBMS_TF", line 220
ORA-06512: at "SYS.DBMS_TF", line 308
ORA-06512: at "ONFTEST.KV2TAB_PKG", line 184
ORA-06512: at "ONFTEST.KV2TAB_PKG", line 187
Listing 7
Better! We get no wrong results but are pointed to the problem in our code! Now it’s time to fix this problem. Just one possible way is to exchange the inner and outer loops, iterate over output columns and then find and assign the corresponding value or otherwise assign NULL, like shown in Listing 8.
...
FOR p IN idcol_cnt+1 .. env.put_columns.count LOOP
found := false;
FOR r IN 1 .. rowcnt LOOP
EXIT WHEN found;
IF inp_rs(idcol_cnt+1).tab_varchar2(r)=replace(env.put_columns(p).name,'"') THEN
found := true;
IF env.put_columns(p).type = dbms_tf.type_varchar2 then
out_rs(p).tab_varchar2(1):= inp_rs(idcol_cnt+2).tab_varchar2(r);
ELSIF env.put_columns(p).type = dbms_tf.type_number then
out_rs(p).tab_number(1):= inp_rs(idcol_cnt+3).tab_number(r);
ELSIF env.put_columns(p).type = dbms_tf.type_date then
out_rs(p).tab_date(1):= inp_rs(idcol_cnt+4).tab_date(r);
END IF;
END IF;
END LOOP;
IF NOT found THEN
IF env.put_columns(p).type = dbms_tf.type_varchar2 then
out_rs(p).tab_varchar2(1):= null;
ELSIF env.put_columns(p).type = dbms_tf.type_number then
out_rs(p).tab_number(1):= null;
ELSIF env.put_columns(p).type = dbms_tf.type_date then
out_rs(p).tab_date(1):= null;
END IF;
END IF;
END LOOP;
...
SQL> SELECT * FROM keyval2tab(t PARTITION BY empno,'T');
EMPNO DEPTNO SAL HIREDATE NEW_COLUMN COMM JOB MGR ENAME
---------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ----------
7369 20 800 1980-12-17 CLERK 7902 SMITH
7499 30 1600 1981-02-20 300 SALESMAN 7698 ALLEN
7521 30 1250 1981-02-22 500 SALESMAN 7698 WARD
7566 20 2975 1981-04-02 MANAGER 7839 JONES
7654 30 1250 1981-09-28 1400 SALESMAN 7698 MARTIN
7698 30 2850 1981-05-01 MANAGER 7839 BLAKE
7782 10 2450 1981-06-09 MANAGER 7839 CLARK
7788 20 3000 1987-04-19 ANALYST 7566 SCOTT
7839 10 5000 1981-11-17 NEW_VALUE PRESIDENT KING
7844 30 1500 1981-09-08 0 SALESMAN 7698 TURNER
7876 20 1100 1987-05-23 CLERK 7788 ADAMS
7900 30 950 1981-12-03 CLERK 7698 JAMES
7902 20 3000 1981-12-03 ANALYST 7566 FORD
7934 10 1300 1982-01-23 CLERK 7782 MILLER
14 rows selected.
Listing 8
Now, everything looks fine again!
Conclusion
We have seen how not populated elements of the collections used in PTF can lead to NO_DATA_FOUND exception. This exception will not be propagated and that can potentially leave you with wrong results. This can not only happen if you are constructing the whole output result set in your PTF and then use DBMS_TF.PUT_ROW_SET. This can just as well happen using DBMS_TF.PUT_COL. As well as with other collection, e.g. with replication factor as mentioned in this post.
I think it is a good idea to catch NO_DATA_FOUND and re-raise it as another user-defined exception. If your processing is wrong in some way, this will make your query fail, instead of returning wrong results (and you have first to figure out they are wrong!) .
This also applies to normal functions (non PTF) used in SQL like shown in Listing 2 and 3. I often used to code the simplest functions without an exception handler at all. Let propagate the error and let the caller decide what should happen. It’s better than WHEN OTHERS THEN NULL anyway 😉 But if there any chance that NO_DATA_FOUND can be thrown – you have to be alert because you will not see it explicitly!