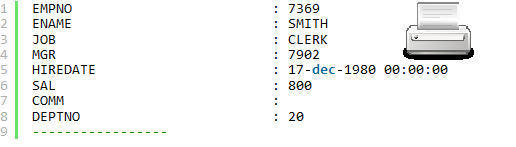
After some weeks of reading and hearing in almost every news report about generative AI and ChatGPT in particular, and how it will change a developer’s life or even make developers obsolete, I was really curious to check it out myself and ask some developer questions. Since I’ve posted quite lot about SQL macros in the past few years, I thought aksing about them could be a good start point. One more argument to start with the topic I’m pretending to know lot about, is to be able to easily distinguish the truth from AI hallucination.
Continue reading
What does ChatGPT “think” about SQL Macros?
Leave a reply