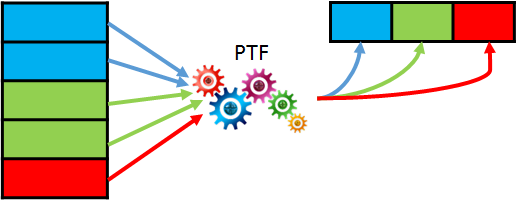
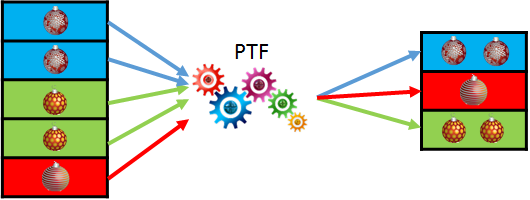
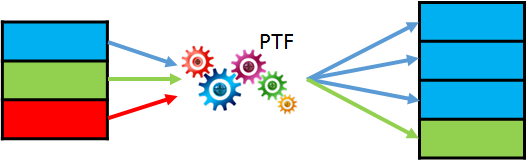
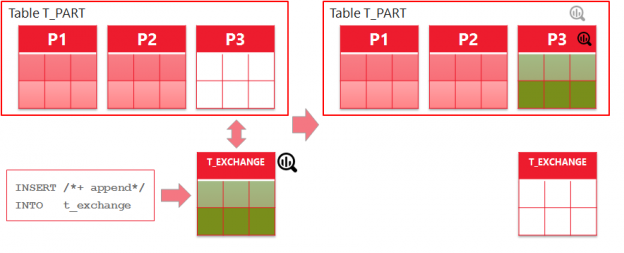
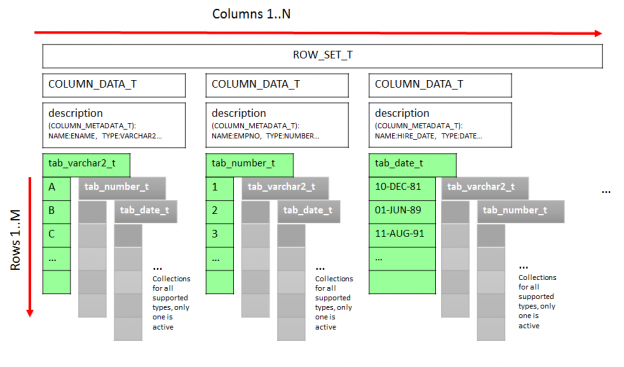
In the next post about SQL macros in Oracle 20c we look at how they could be useful for building hash keys. If you are familiar with Data Warehousing and Data Vault modelling approach, you will probably know why it can be a good idea to build hash keys or hash diffs. Anyway, we will not discuss whether or not you should use them, but rather how you can do this in Oracle in a consistent and performant way.
Continue reading
Building Hash Keys using SQL Macros in Oracle 20c
5 Replies