
In the first part of PTF series we went through a very basic example removing some columns and adding a new column with a constant value. Starting from the same example we’ll do something more meaningful in the second part. How about concatenating the values of the removed columns as CSV in a new column?
First, let’s extend the table we were using in Part 1 just to have some more columns to test with:
DROP TABLE t; CREATE TABLE t (A NUMBER, B NUMBER, C NUMBER, V VARCHAR2(10)); INSERT INTO t VALUES (1,2,3, 'ONE'); INSERT INTO t VALUES (4,5,6, 'TWO'); INSERT INTO t VALUES (7,8,9, 'THREE'); COMMIT;
Listing 1: Setup
Back to the task. How should the PTF look like? What parameters do we need? Let’s make the function to accept a list of columns to stay. All remaining columns will be concatenated, so that we don’t need a separate list for them. Additionally we need a new column name. We can define a default column name and make this parameter optional though.
CREATE OR REPLACE PACKAGE my_ptf_package AS
FUNCTION describe (tab IN OUT dbms_tf.table_t
, cols2stay IN dbms_tf.columns_t
, new_col_name IN DBMS_ID DEFAULT 'AGG_COL')
RETURN dbms_tf.describe_t;
PROCEDURE fetch_rows (new_col_name IN DBMS_ID DEFAULT 'AGG_COL');
END my_ptf_package;
/
Listing 2: package specification
The implementation of the DESCRIBE method looks very similar to that from Part 1. We just changed the semantic of the columns parameter.
CREATE OR REPLACE PACKAGE BODY my_ptf_package AS
FUNCTION describe (tab IN OUT dbms_tf.table_t
, cols2stay IN dbms_tf.columns_t
, new_col_name IN DBMS_ID DEFAULT 'AGG_COL')
RETURN dbms_tf.describe_t IS
BEGIN
FOR I IN 1 .. tab.COLUMN.COUNT LOOP
IF NOT tab.COLUMN(i).description.name MEMBER OF cols2stay THEN
tab.column(i).pass_through := false;
tab.column(i).for_read := true;
END IF;
END LOOP;
RETURN dbms_tf.describe_t(
new_columns =>
dbms_tf.columns_new_t(
1 => dbms_tf.column_metadata_t(
name => new_col_name,
TYPE => dbms_tf.type_varchar2)));
END;
...
Listing 3: DESCRIBE method
FETCH_ROWS
Now let’s look at the implementation of FETCH_ROWS. As we already know from Part 1, FETCH_ROWS can be called multiple times, but we don’t need to concern about this. Just fetch, process and output. How to do this? What tools do we have? Well, there are two methods, both are somewhat complicated in their own way, but the combination of both methods looks better. Take a little popcorn: it will take some time. We’ll look at both pure methods first and then at their combination, looking at some other little things like tracing as well.
Working with row sets
The implementation of the FETCH_ROWS is shown in Listing 4. We are working with the table type ROW_SET_T here, using variables of this type for fetching the data into (inp_rs) and as an output structure (out_rs) as well. For clarity, I’ll include the picture, we’ve seen in the first part again:
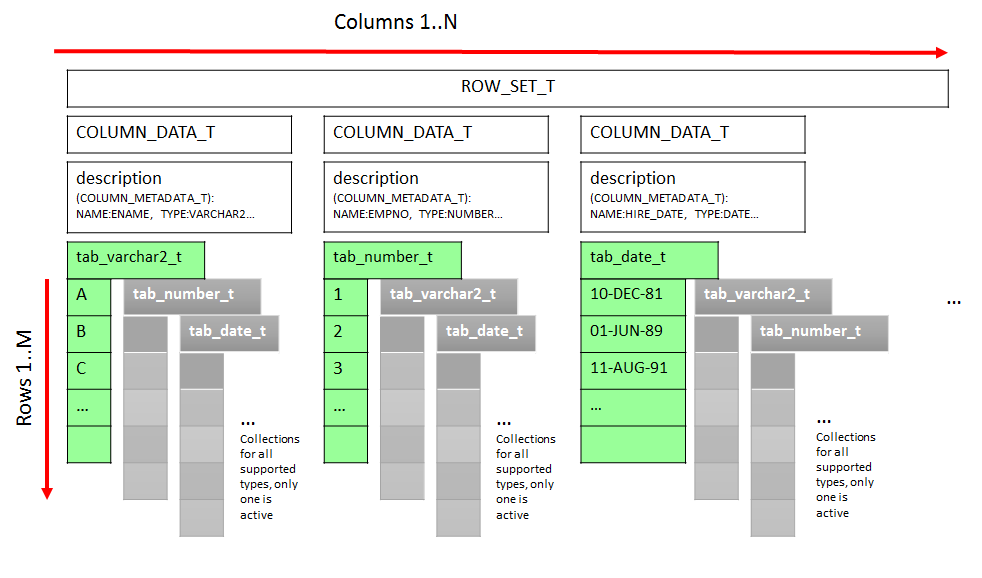
To fetch the values of the columns of interest we use the procedure dbms_tf.get_row_set (line 7). It fetches only the columns marked as FOR_READ into the data structure of the shown type dbms_tf.row_set_t returning also the row and column count.
Now, our task is to loop through rows (line 8) and columns (line 10) and produce the desired output. We are using dbms_tf.col_to_char for that (line 13). This function converts the column value to its string representation and expects column data collection – inp_rs(c) in our case – and the row number as parameters.
We are assigning concatenated values directly to the elements of VARCHAR2 collection of the output row set out_rs. Because we have only one column to output, we can just use out_rs(1). I find this kind of referencing nested structured types and arrays to be rather complicated.
After the loop we use dbms_tf.put_row_set to pass the output row set back to the database (to the main query).
PROCEDURE fetch_rows(new_col_name IN DBMS_ID DEFAULT 'AGG_COL') IS
inp_rs dbms_tf.row_set_t;
colcnt PLS_INTEGER;
rowcnt PLS_INTEGER;
out_rs dbms_tf.row_set_t;
BEGIN
dbms_tf.get_row_set(inp_rs, rowcnt, colcnt);
FOR r IN 1..rowcnt LOOP
out_rs(1).tab_varchar2(r) := '';
FOR c IN 1..colcnt LOOP
out_rs(1).tab_varchar2(r) :=
out_rs(1).tab_varchar2(r)||
';'||DBMS_TF.COL_TO_CHAR(inp_rs(c), r);
END LOOP;
out_rs(1).tab_varchar2(r) :=
ltrim (out_rs(1).tab_varchar2(r) ,';');
END LOOP;
dbms_tf.put_row_set(out_rs);
END;
...
SQL> SELECT * FROM my_ptf(t, COLUMNS(A));
A AGG_COL
---------- --------------------
1 2;3;"ONE"
4 5;6;"TWO"
7 8;9;"THREE"
Listing 4: FETCH_ROWS procedure with get_row_set/put_row_set
We have two row sets here: input and output. Why two of them? What is the difference? Could we only use one? Basically, no, we can’t. The columns in the input row set are those, that we have defined as FOR_READ in the DESCRIBE method. They are called GET-columns in context of FETCH_ROWS. The columns in the output row set are in turn those that we have returned as NEW_COLUMNS from DESCRIBE method. They are called PUT-columns here.
Having played with PTF’s for a while now, I have often made experience that after some change the PTF just stopped working, leaving the result (new columns) empty. Most of the time the reason for this was careless handling of row sets. I’ve made some tests to better understand the interrelationships and put them into a separate post to avoid blowing up this post.
The main findings:
- the output rowset holds only PUT-columns
- the order of columns is as defined in DESCRIBE (new columns), column names are not taken into account
- always populate row sets to be dense. They are not allowed to be sparse.
- adding columns to rowset will have no impact, if not declared in DESCRIBE altogether
Working with individual columns
Besides the possibility to work with the whole row sets, DBMS_TF also provides procedures to fetch and output the values of particular columns: get_col and put_col. As parameters they expect a ColumnId and a collection to fetch data into or holding new data respectively. What’s the hell is this ColumnId now? It is the column number in the order as created in DESCRIBE method. The PTF gets the table parameter containing column metadata and thus also the column order. We then make some or all of these columns to be FOR_READ. This gives the order of GET-columns, which is relevant for get_col. We also define new columns, which are the part of the return datatype DESCRIBE_T. This in turn gives the order of PUT-columns to use with put_col. Remember, they are not the same. The same ColumnId is likely to mean different columns in GET and PUT rowsets.
Caution! There is a Copy&Paste mistake in the documentation of put_col:
This procedure is used to put the read column values in the collection of scalar type.
The column numbers are in the get column order as created in DESCRIBE method of PTF.
These two sentences are just misleading. they should rather be something like this:
This procedure is used to put the collection of scalar type back to the query. The column numbers are in the put column order as created in DESCRIBE method of PTF.
The rough planning will be to fetch the read-columns, process them in a loop and pass the result back. But using get_col to fetch doesn’t return the number of rows like get_row_set does. So, what can we do? There is a record type ENV_T, which can be filled with dbms_tf.get_env and contains the metadata about the PTF’s execution state, including the number of rows, get and put column lists and so on.
We’ll turn some tracing on to see what the content of the ENV-record is. The package DBMS_TF provides several overloaded functions TRACE, the one that acts just like dbms_output.put_line, whereas others accept various structured types as parameter and present their content in the pretty manner. We’ll use the one to output the content of the ENV_T record.
Having that start point with ENV_T, we can now implement the loop through get columns and use their values producing the result.
...
PROCEDURE fetch_rows(new_col_name IN DBMS_ID DEFAULT 'AGG_COL') IS
data_col dbms_tf.column_data_t;
agg_col dbms_tf.tab_varchar2_t;
env dbms_tf.env_t := dbms_tf.get_env();
BEGIN
dbms_tf.trace(env);
FOR r IN 1..env.row_count LOOP
agg_col(r) := '';
END LOOP;
FOR i IN 1..env.get_columns.count LOOP
IF env.get_columns(i).type = dbms_tf.type_varchar2 THEN
dbms_tf.get_col(i, data_col.tab_varchar2);
data_col.description.type := dbms_tf.type_varchar2;
ELSIF env.get_columns(i).type = dbms_tf.type_number THEN
dbms_tf.get_col(i, data_col.tab_number);
data_col.description.type := dbms_tf.type_number;
END IF;
FOR r IN 1..env.row_count LOOP
agg_col(r) := agg_col(r)||';'||
DBMS_TF.COL_TO_CHAR(data_col, r);
END LOOP;
END LOOP;
FOR r IN 1..env.row_count LOOP
agg_col(r) := ltrim (agg_col(r) ,';');
END LOOP;
dbms_tf.put_col(1,agg_col);
END;
...
SQL> SELECT * FROM my_ptf(t, COLUMNS(A));
A AGG_COL
---------- --------------------
1 2;3;"ONE"
4 5;6;"TWO"
7 8;9;"THREE"
Current Parallel Environment:
....Instance id:..........65535
....Session id:...........65535
....Slave Server Grouup:..65535
....Slave Set number:.....65535
....No of Sibling Slaves:.-1
....Global Slave Number:..-1
....No of local Slaves:...-1
....Local Slave No:.......-1
....Get Columns:
........get column[1] =
__________Type:...............NUMBER
__________Max Length:.........22
__________Name:..............."B"
__________Name Length:........3
__________Precision:..........0
__________Scale:..............-127
........get column[2] =
__________Type:...............NUMBER
__________Max Length:.........22
__________Name:..............."C"
__________Name Length:........3
__________Precision:..........0
__________Scale:..............-127
........get column[3] =
__________Type:...............VARCHAR2
__________Max Length:.........10
__________Name:..............."V"
__________Name Length:........3
__________Charset Id:.........AL32UTF8
__________Collation:..........USING_NLS_COMP
....Put Columns:
........put column[1] =
__________Type:...............VARCHAR2
__________Max Length:.........4000
__________Name:..............."AGG_COL"
__________Name Length:........9
__________Charset Id:.........AL32UTF8
__________Collation:..........USING_NLS_COMP
....Referenced Columns:
........ column[1] = "AGG_COL" referenced
.... This is User query
....Numbers of rows in this row set: 3
Listing 5: FETCH_ROWS procedure with get_col/put_col
As you can see, there is more to do: you have to know the columns datatype to choose the right collection, otherwise, you’ll get ORA-62559: Data types mismatch (NUMBER<<==>>VARCHAR) for polymorphic table function. We are also doing the loops and concatenation in a different way: instead of concatenating all columns in the loop for all rows we are now looping through columns, concatenating just one column for all rows at a time.
Combining the two approaches
With first approach populating of the output was some kind of inconvinient, and with the second one – fetching of incoming data. Taking the fact into account that maybe in most situations you will have more input as output columns, it will be a good idea to try to combine both approaches. We just use dbms_tf.get_row_set to fetch the for_read columns and use dbms_tf.put_col for output.
...
PROCEDURE fetch_rows IS
rowset dbms_tf.row_set_t;
colcnt PLS_INTEGER;
rowcnt PLS_INTEGER;
agg_col dbms_tf.tab_varchar2_t;
BEGIN
dbms_tf.get_row_set(rowset, rowcnt, colcnt);
FOR r IN 1..rowcnt LOOP
agg_col(r) := '';
FOR c IN 1..colcnt LOOP
agg_col(r) := agg_col(r)||';'
||DBMS_TF.COL_TO_CHAR(rowset(c), r);
END LOOP;
agg_col(r) := ltrim (agg_col(r) ,';');
END LOOP;
dbms_tf.put_col(1, agg_col);
END;
...
SQL> SELECT * FROM my_ptf(t, COLUMNS(A));
A AGG_COL
---------- ----------------
1 2;3;"ONE"
4 5;6;"TWO"
7 8;9;"THREE"
SQL> SELECT * FROM my_ptf(t, COLUMNS(A,B));
A B AGG_COL
---------- ---------- ---------------
1 2 3;"ONE"
4 5 6;"TWO"
7 8 9;"THREE"
SQL> SELECT * FROM my_ptf(scott.emp, COLUMNS(empno));
EMPNO AGG_COL
---------- --------------------------------------------------
7369 "SMITH";"CLERK";7902;"17-DEC-80";800;;20
7499 "ALLEN";"SALESMAN";7698;"20-FEB-81";1600;300;30
7521 "WARD";"SALESMAN";7698;"22-FEB-81";1250;500;30
Listing 6: FETCH_ROWS procedure with get_row_set/put_col
Simple, isn’t it? No headaches with fetching and collections of proper datatype, no need for environment record, just one collection for output, whose population is simple too. And you can see the polymorphism in action: the same PTF returns diffenet output shape depending on parameters and input table.
JSON
Now what if we wanted a JSON-document instead of a CSV? Nothing easier than that! The function DBMS_TF.ROW_TO_CHAR does exactly that: converts the whole rowset to its string representation. The third parameter allows us to choose the desired format, dbms_tf.format_json in our case. I’m kidding 😉 JSON is the only supported format at the moment. But it would be nice to have also CSV, would it?
...
PROCEDURE fetch_rows IS
rowset dbms_tf.row_set_t;
rowcnt PLS_INTEGER;
json_col dbms_tf.tab_varchar2_t;
BEGIN
dbms_tf.get_row_set(rowset, rowcnt);
FOR r IN 1..rowcnt LOOP
json_col(r) := DBMS_TF.ROW_TO_CHAR(rowset, r,
DBMS_TF.FORMAT_JSON);
END LOOP;
dbms_tf.put_col(1, json_col);
END;
...
SQL> SELECT * FROM split_json(t, COLUMNS(A));
A JSON_COL
---------- -------------------------------------
1 {"B":2, "C":3, "V":"ONE"}
4 {"B":5, "C":6, "V":"TWO"}
7 {"B":8, "C":9, "V":"THREE"}
Listing 7: FETCH_ROWS is generating JSON output
What’s next?
We have now seen, how processing in FETCH_ROWS can be organized, how to produce new values using the input data (FOR_READ columns). But so far we’ve only covered the simplest cases of the row-semantic PTF. All needed columns were the part of the same row and we produced just as many rows as the input table had.
In the next section we will cover row replication and see how to produce less or more rows than the input data flow has.
Hello Andrej,
Again, I cannot thank you enough for another excellent post 🙂
Your explanations are amazing, this is exactly what I was expecting for getting a deep understanding
of this topic 🙂 🙂
I am already waiting eagerly for your further posts 🙂 🙂
Thanks a lot for you excellent work & Best Regards,
Iudith Mentzel