
Maintaining a data historization is a very common but time consuming task in a data warehouse environment. You face it while loading historized Core-Layer (also known as Enterprise Data Warehouse or Foundation Layer), Data Vault Models, Slowly Changing Dimensions, etc. The common techniques used involve outer joins and some kind of change detection. This change detection must be done with respect of Null-values and is possibly the most trickiest part. A very good overview by Dani Schnider can be found in his blog: Delta Detection in Oracle SQL
But, on the other hand, SQL offers standard functionality with exactly desired behaviour: Group By or Partitioning with analytic functions. Can it be used for this task? Does it make sense? And how would the ETL process look like? Can we further speed up the task using partition exchange and when does it make sense? I’ll look at this in the next few posts.
Introduction and common approach
First of all, I suppose you are familiar with the historization and temporal validity concepts to some extent. We consider so called Slowly Changing Dimensions Type 2. But this historization schema does not apply only for dimensions.
Consider following example. We have a source table which must be loaded into the target table on a daily basis. The target table has validity date columns and allows multiple versions for one business key. If we detect changes in the data for some business key, we close (set the valid_to date) the current version and open a new one with the new data. No meaningful data will be replaced, all changes will be completely trackable over time.
whenever sqlerror continue
drop table t_source purge;
drop table t_target purge;
drop sequence scd2_seq ;
create sequence scd2_seq ;
--Source Table
create table t_source
( load_date date
, business_key varchar2(5)
, first_name varchar2(50)
, second_names varchar2(100)
, last_name varchar(50)
, hire_date date
, fire_date date
, salary number(10));
-- Target Table
create table t_target
( dwh_key number
, dwh_valid_from date
, dwh_valid_to date
, current_version char(1 byte)
, etl_op varchar2(3 byte)
, business_key varchar2(5)
, first_name varchar2(50)
, second_names varchar2(100)
, last_name varchar(50)
, hire_date date
, fire_date date
, salary number(10));
insert into t_source (load_date, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(DATE '2016-12-01', '123', 'Roger', null, 'Federer', DATE '2010-01-01', null, 900000);
insert into t_source (load_date, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(DATE '2016-12-01', '456', 'Rafael', null, 'Nadal', DATE '2009-05-01', null, 720000);
insert into t_source (load_date, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(DATE '2016-12-01', '789', 'Serena', null, 'Williams', DATE '2008-06-01', null, 650000);
-- We simulate the first ETL run and simply insert our data in the target table
insert into t_target (dwh_key, dwh_valid_from, dwh_valid_to, current_version, etl_op, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(scd2_seq.nextval, DATE '2016-12-01', null, 'Y', 'INS', '123', 'Roger', null, 'Federer', DATE '2010-01-01', null, 900000);
insert into t_target (dwh_key, dwh_valid_from, dwh_valid_to, current_version, etl_op, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(scd2_seq.nextval, DATE '2016-12-01', null, 'Y', 'INS', '456', 'Rafael', null, 'Nadal', DATE '2009-05-01', null, 720000);
insert into t_target (dwh_key, dwh_valid_from, dwh_valid_to, current_version, etl_op, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(scd2_seq.nextval, DATE '2016-12-01', null, 'Y', 'INS', '789', 'Serena', null, 'Williams', DATE '2008-06-01', null, 650000);
commit;
The most common approach I have seen involves outer joining the source table with the current versions in the target table based on the business key. If we have the business key only on one side of the join, we are dealing with the new or deleted records. If the key is on both sides, we must check for data changes. To be able to close the old versions and insert the new ones in one MERGE Statement we use some split technique and then combine the old and new records with a UNION ALL. Again, the whole approach is very well described here: Delta Detection in Oracle SQL
The typical pattren of the ETL process looks in Oracle Warehouse Builder something like this:
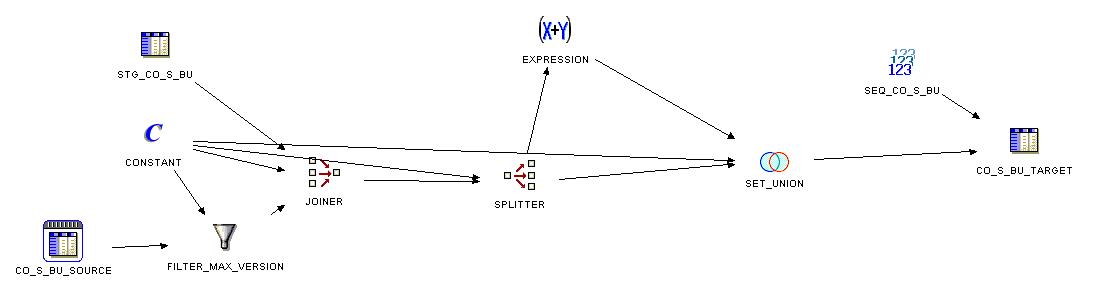
Pretty much work. The drawback of the Oracle Warehouse Builder implementation is that the source and target tables will be scanned an joined twice. So how can we do it better?
Another approach
Imagine, next day we’ve got the new data in the source:
-- Next we get new data in the source
delete from t_source;
insert into t_source (load_date, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(DATE '2016-12-02', '123', 'Roger', null, 'Federer', DATE '2010-01-01', null, 900000);
insert into t_source (load_date, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(DATE '2016-12-02', '456', 'Rafael', null, 'Nadal', DATE '2009-05-01', null, 720000);
-- New Second_name
insert into t_source (load_date, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(DATE '2016-12-02', '789', 'Serena', 'Jameka', 'Williams', DATE '2008-06-01', null, 650000);
--new record
insert into t_source (load_date, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(DATE '2016-12-02', '345', 'Venus', null, 'Williams', DATE '2016-11-01', null, 500000);
commit;
For Business Key 789 (Serena Williams) we get the second name instead of an empty (NULL) value. The Business Key 345 (Venus Williams) is new.
Now we have following content in our tables:
select * from t_source;
LOAD_DATE BUS FIRST_NAME SECOND_NAM LAST_NAME HIRE_DATE FIRE_DATE SALARY
---------- --- ---------- ---------- ---------- ---------- ---------- ----------
2016-12-02 123 Roger Federer 2010-01-01 900000
2016-12-02 456 Rafael Nadal 2009-05-01 720000
2016-12-02 789 Serena Jameka Williams 2008-06-01 650000
2016-12-02 345 Venus Williams 2016-11-01 500000
4 rows selected.
select * from t_target;
DWH_KEY DWH_VALID_ DWH_VALID_ C ETL_OP BUS FIRST_NAME SECOND_NAM LAST_NAME HIRE_DATE FIRE_DATE SALARY
---------- ---------- ---------- - ------ --- ---------- ---------- ---------- ---------- ---------- ----------
1 2016-12-01 Y INS 123 Roger Federer 2010-01-01 900000
2 2016-12-01 Y INS 456 Rafael Nadal 2009-05-01 720000
3 2016-12-01 Y INS 789 Serena Williams 2008-06-01 650000
3 rows selected.
Step 1
We must compare the source data with the current versions in the target table. It might be not so straightforward, but let combine them with a UNION operator at first step:
-- The current versions in the target table select 'T' source_target -- to distinguish these records later , business_key , dwh_valid_from , first_name , second_names , last_name , hire_date , fire_date , salary from t_target where current_version = 'Y' -- Now the new data -- put them together with UNION ALL union all select 'S' source_target , business_key , load_date dwh_valid_from -- we use load_date as the new validity start date , first_name , second_names , last_name , hire_date , fire_date , salary from t_source; S BUS DWH_VALID_ FIRST_NAME SECOND_NAM LAST_NAME HIRE_DATE FIRE_DATE SALARY - --- ---------- ---------- ---------- ---------- ---------- ---------- ---------- T 123 2016-12-01 Roger Federer 2010-01-01 900000 T 456 2016-12-01 Rafael Nadal 2009-05-01 720000 T 789 2016-12-01 Serena Williams 2008-06-01 650000 S 123 2016-12-02 Roger Federer 2010-01-01 900000 S 456 2016-12-02 Rafael Nadal 2009-05-01 720000 S 789 2016-12-02 Serena Jameka Williams 2008-06-01 650000 S 345 2016-12-02 Venus Williams 2016-11-01 500000 7 rows selected.
We add the column SOURCE_TARGET which can be ‘T’ or ‘S’ to distinguish between the records coming from target and source tables.
Note that we can have at most two records per business key in this result set. Possible cases are:
- The tracked columns of those two records can be exactly the same – no action needed
- The tracked columns could be changed – must detect this, close the current version and open a new one
- There can be only one record per business key if we have a new record that is not yet in target or if the record was deleted in source
Step 2
So let us simply count records per business key and columns to be tracked using the analytic function count(). The most interesting part is in line 32. The Partioning Clause is the business_key and all columns to be tracked. This partitioning clause is doing the whole change detection work for us. Its behaviour regarding nulls is exactly what we want: NULL=NULL and NULL!=VALUE. If we have some change, we will have another partition. If we have no change, both old and new records will be in one partition.
with union_source_target as ( -- What are the current versions in the target table select 'T' source_target -- to distinguish these records later , business_key , dwh_valid_from , first_name , second_names , last_name , hire_date , fire_date , salary from t_target where current_version = 'Y' -- Now the new data -- put them together with UNION ALL union all select 'S' source_target , business_key , load_date dwh_valid_from -- we use load_date as the new validity start date , first_name , second_names , last_name , hire_date , fire_date , salary from t_source ) select un.* -- we need NVL for the records which were deleted in source in case we must "close" them. The constant means for example load date and can be returned from PL/SQL function , nvl(lead (dwh_valid_from ) over(partition by business_key order by dwh_valid_from) - 1, DATE '2016-12-02' ) new_dwh_valid_to , count(*) over (partition by business_key, first_name, second_names, last_name, hire_date, fire_date, salary) cnt -- cnt = 2 - two versions are the same, otherwise INS/UPD/DEL , count(*) over (partition by business_key) cnt_key -- the count of versions per business_key from union_source_target un;
Step 3
So how can we use the information gained at step 2? If the count is equal two, then we have two identical records – nothing to do. Otherwise we must handle Insert, Update or Delete. We can show the expected actions with the following query. Actually we don’t need it, this is only to show what will happen.
-- Filter only the records where some action is needed and show what kind of action
with union_source_target as
(
-- What are the current versions in the target table
select 'T' source_target -- to distinguish these records later
, business_key
, dwh_valid_from
, first_name
, second_names
, last_name
, hire_date
, fire_date
, salary
from t_target
where current_version = 'Y'
-- Now the new data
-- put them together with UNION ALL
union all
select 'S' source_target
, business_key
, load_date dwh_valid_from -- we use load_date as the new validity start date
, first_name
, second_names
, last_name
, hire_date
, fire_date
, salary
from t_source
)
, action_needed as
(
select un.*
-- we need NVL for the records which were deleted in source in case we must "close" them. The constant means for example load date and can be returned from PL/SQL function
, nvl(lead (dwh_valid_from ) over(partition by business_key order by dwh_valid_from) - 1, DATE '2016-12-02' ) new_dwh_valid_to
, count(*) over (partition by business_key, first_name, second_names, last_name, hire_date, fire_date, salary) cnt -- cnt = 2 - two versions are the same, otherwise INS/UPD/DEL
, count(*) over (partition by business_key) cnt_key -- the count of versions per business_key (in this result set only, not in the target table)
from union_source_target un
)
select an.*
, case
when source_target = 'T' and cnt_key > 1 then 'Close this version (new version will be added)'
when source_target = 'T' and cnt_key = 1 then 'Close this version (no new version will be added, the record was deleted in source)'
when source_target = 'S' then 'Insert new version'
end action
from action_needed an
where cnt != 2
S BUS DWH_VALID_ FIRST_NAME SECOND_NAM LAST_NAME HIRE_DATE FIRE_DATE SALARY NEW_DWH_VALID_TO CNT CNT_KEY ACTION
- --- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ---------------- --- ------- --------------------------------------------------
S 345 2016-12-02 Venus Williams 2016-11-01 500000 2016-12-02 1 1 Insert new version
T 789 2016-12-01 Serena Williams 2008-06-01 650000 2016-12-01 1 2 Close this version (new version will be added)
S 789 2016-12-02 Serena Jameka Williams 2008-06-01 650000 2016-12-02 1 2 Insert new version
3 rows selected.
Step 4
The actions are as expected and now we are ready to merge this result set into the target table:
merge into t_target t
using (
with union_source_target as
(
-- What are the current versions in the target table
select 'T' source_target -- to distinguish these records later
, business_key
, dwh_valid_from
, first_name
, second_names
, last_name
, hire_date
, fire_date
, salary
from t_target
where current_version = 'Y'
-- Now the new data
-- put them together with UNION ALL
union all
select 'S' source_target
, business_key
, load_date dwh_valid_from -- we use load_date as the new validity start date
, first_name
, second_names
, last_name
, hire_date
, fire_date
, salary
from t_source
)
, action_needed as
(
select un.*
-- we need NVL for the records which were deleted in source in case we must "close" them. The constant means for example load date and can be returned from PL/SQL function
, nvl(lead (dwh_valid_from ) over(partition by business_key order by dwh_valid_from) - 1, DATE '2016-12-02' ) new_dwh_valid_to
, count(*) over (partition by business_key, first_name, second_names, last_name, hire_date, fire_date, salary) cnt -- cnt = 2 - two versions are the same, otherwise INS/UPD/DEL
, count(*) over (partition by business_key) cnt_key -- the count of versions per business_key (in this result set only, not in the target table)
from union_source_target un
)
select an.*
, case
when source_target = 'T' and cnt_key > 1 then 'Close this version (new version will be added)'
when source_target = 'T' and cnt_key = 1 then 'Close this version (no new version will be added, the record was deleted in source)'
when source_target = 'S' then 'Insert new version'
end action
from action_needed an
where cnt != 2
) q
on ( t.business_key = q.business_key and t.dwh_valid_from = q.dwh_valid_from )
when not matched then insert ( dwh_key
, dwh_valid_from
, dwh_valid_to
, current_version
, etl_op
, business_key
, first_name
, second_names
, last_name
, hire_date
, fire_date
, salary )
values ( scd2_seq.nextval
, q.dwh_valid_from
, NULL -- NULL means no end date
, 'Y'
, 'INS'
, q.business_key
, q.first_name
, q.second_names
, q.last_name
, q.hire_date
, q.fire_date
, q.salary )
when matched then update set
t.dwh_valid_to = q.new_dwh_valid_to
, t.current_version = 'N'
, t.etl_op = 'UPD';
We are done with it! What is in the target table after the merge? Exactly what we’ve expected: the new version for Venus Williams and the new version for Serena Williams. Both are valid from 2016-12-02, our load date. The old version for Serena Williams was closed with valid_to date of 2016-12-01.
select *
from t_target
order by business_key, dwh_valid_from;
DWH_KEY DWH_VALID_ DWH_VALID_ C ETL_OP BUS FIRST_NAME SECOND_NAM LAST_NAME HIRE_DATE FIRE_DATE SALARY
---------- ---------- ---------- - ------ --- ---------- ---------- ---------- ---------- ---------- ----------
1 2016-12-01 Y INS 123 Roger Federer 2010-01-01 900000
6 2016-12-02 Y INS 345 Venus Williams 2016-11-01 500000
2 2016-12-01 Y INS 456 Rafael Nadal 2009-05-01 720000
3 2016-12-01 2016-12-01 N UPD 789 Serena Williams 2008-06-01 650000
5 2016-12-02 Y INS 789 Serena Jameka Williams 2008-06-01 650000
5 rows selected.
One more test, the next load on 2016-12-03. We change number column SALARY, date column FIRE_DATE and Rafael Nadal is not in the source any more:
delete from t_source;
-- Salary changed
insert into t_source (load_date, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(DATE '2016-12-03', '123', 'Roger', null, 'Federer', DATE '2010-01-01', null, 920000);
-- Business_key = 456 is not there anymore
-- No change
insert into t_source (load_date, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(DATE '2016-12-03', '789', 'Serena', 'Jameka', 'Williams', DATE '2008-06-01', null, 650000);
-- Change in fire_date
insert into t_source (load_date, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(DATE '2016-12-03', '345', 'Venus', null, 'Williams', DATE '2016-11-01', DATE '2016-12-01', 500000);
commit;
MERGE
...
select *
from t_target
order by business_key, dwh_valid_from;
DWH_KEY DWH_VALID_ DWH_VALID_ C ETL_OP BUS FIRST_NAME SECOND_NAM LAST_NAME HIRE_DATE FIRE_DATE SALARY
---------- ---------- ---------- - ------ --- ---------- ---------- ---------- ---------- ---------- ----------
1 2016-12-01 2016-12-02 N UPD 123 Roger Federer 2010-01-01 900000
11 2016-12-03 Y INS 123 Roger Federer 2010-01-01 920000
6 2016-12-02 2016-12-02 N UPD 345 Venus Williams 2016-11-01 500000
10 2016-12-03 Y INS 345 Venus Williams 2016-11-01 2016-12-01 500000
2 2016-12-01 2016-12-02 N UPD 456 Rafael Nadal 2009-05-01 720000
3 2016-12-01 2016-12-01 N UPD 789 Serena Williams 2008-06-01 650000
5 2016-12-02 Y INS 789 Serena Jameka Williams 2008-06-01 650000
7 rows selected.
As you can see, Roger Federer got a salary raise and a new version, Venus Willaims was fired and got a new version too. The record for Rafael Nadal was deleted in the source. We have recognized that and set an appropriate valid_to date.
One could certainly argue about the best startegy to handle temporal validity. How can I define infinity, with NULL values as I did, or with some special values, e.g. 9999-12-31? Does it make sense to use some kind of current_version (Yes/No) column? Is it better to have Valid_to equal to Valid_from of the following version? In our example we have one day gap between them. What is the best strategy to handle deleted records? All of this are reasonable questions, of course, but not the point here. With this approach we have enough information to implement all of the possible strategies.
Conclusion
It looks very simple but nevertheless does the right thing! We can avoid an outer join. We can avoid complex change detection with NVL, buildng row hashes or the like. The source will be scanned only once, which can be very important if we are dealing with some complex view as a source. Even more, we have a UNION instead of a join – in 12c both branches of the UNION operator can be executed concurrently.
I will do some further investigation, compare perfromance, look at parallel execution, etc. and share results here. Is it possible to change the statement so that SCD1 columns could be handled as well? Another interesting alternative I have tested is also based on the same approach but uses a multi-table insert instead of a merge and partition exchange afterwards. I’ll describe this in one of my next posts.
wow! Would this work (performance wise) for Teradata as well?
Hi Arne,
Unfortunately, I have no access to Teradata. I assume it will work too but I can’t make any assumptions about performance. Maybe you can test it and post your observations?
Regards
Andrej
do you have any performance result with this method finally ?
thx.
Yes, you can find some results in the follow-up post