
In the previous post I have shown how to use a combination of a UNION ALL and a GROUP BY to do a slowly changing dimension type 2 data historization. I’ve done some tests since then to compare performance of this approach with common methods in various situations.
Test case #1
Let’s consider loading of a versioned table in a data warehouse core area from the table in a staging area. Let’s first look at the possible shapes in terms of data volume and where the performance could suffer. Basically, there are two possibilities to implement the ETL process: full loading and delta loading.
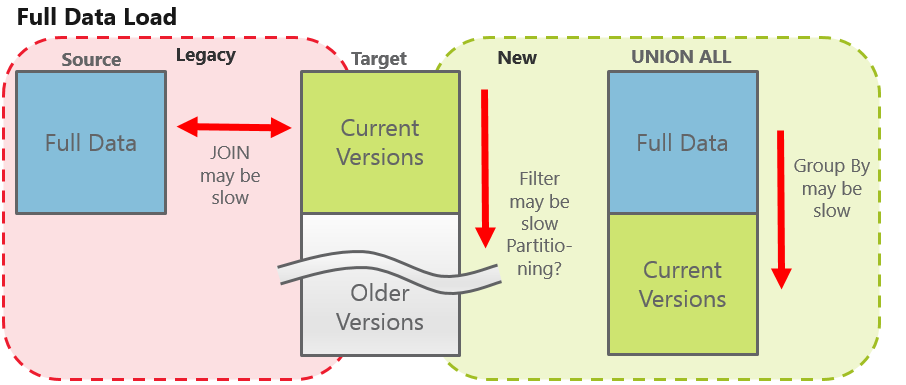
Full loading
With full data loading we have full data extract in the staging area. Now, with legacy approach, joining it to the whole valid records in the core table might be slow. And remember, this needs to be done twice unless we decide to materialize the intermediate results of our ETL process.
But in turn, with the “new” approach, we have to group over a data set, which is twice as big as the full extract – this can be quite slow too!
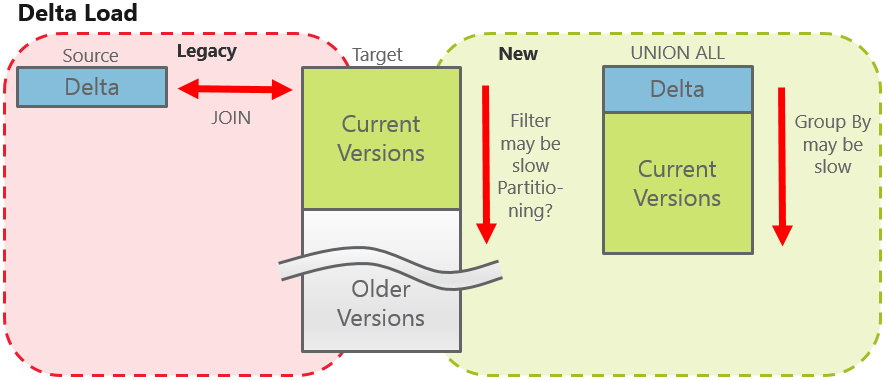
Delta loading
With delta loading we have only a small set of the new and changed records in a stage table. Thus, the join to the valid records from the core table can be quite efficient, whereas with the “new” approach we have to group over a still “big” data set: all current records plus “delta”. How can we address that issue?
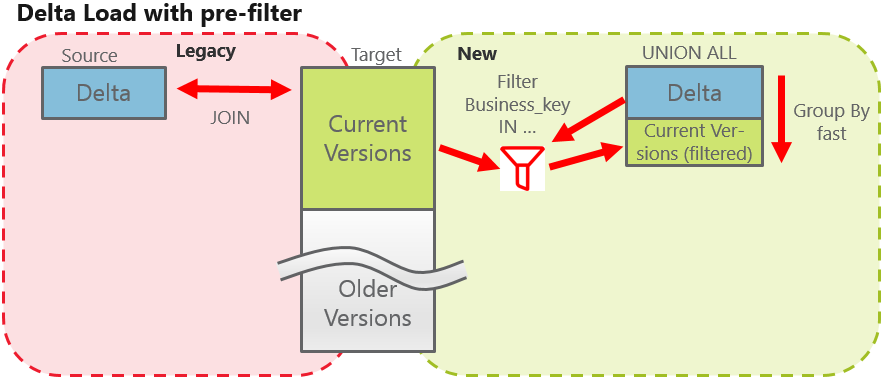
Delta loading with pre-filter
Obviously, we only need to compare those records which already exist in the core table. So we can build in some kind of pre-filter, e.g. using an IN- or EXISTS-subquery on a business key. Thus, we only need to group over a data set which is roughly twice so big as the delta extract.
Here are some basic conditions and figures of my test case:
- rather wide table with 120 columns
- comparing legacy approach vs. GROUP BY vs. analytical functions
- full data extract in a staging table as a source vs. delta (with or without pre-filtering)
- ca. 6 millions rows in the target table
- ca. 3 millions rows in the full load data set
- ca. 3000 rows in the delta load data set
| Method | Delta Load, min | Full Load, min |
|---|---|---|
| Outer Join (legacy) | 0:09 | 0:41 |
| GROUP BY | 1:10 | 1:04 |
| GROUP BY with pre-filter | 0:04 | N/A |
| Analytic Function | 2:12 | 4:52 |
| Analytic Function with pre-filter | 0:12 | N/A |
When loading only delta extract, the legacy approach is pretty good from the performance point of view. It is its complexity, comparing each and every column or building, saving and comparing “hash_diffs” for the whole rows, which was the reason to search for an alternative approach. On the other hand, the pure GROUP BY approach is simple but significantly slower. The same GROUP BY with pre-filter is the winner, but the price is again slightly increased complexity.
With full loading the new approach cannot keep up with a join – it is about 50% slower.
To understand the difference between using GROUP BY and analytic functions we must look at the execution plans of the queries. Until Oracle 10g Release 2 grouping was done using SORT GROUP BY operation. And that is comparable with the WINDOW SORT operation, which we see if we use the analytical function COUNT(). With 10g Release 2 the hash aggregation was introduced. We can recognize it by seeing the HASH GROUP BY step in the execution plan (Listing 1 line 21). But analytical functions don’t use hash aggregation, most of the time get lost on lines 14 and 15 (Listing 2) – WINDOW SORT
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | TQ |IN-OUT| PQ Distrib | A-Rows | A-Time | Buffers | Reads | OMem | 1Mem | O/1/M |
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
| 0 | MERGE STATEMENT | | 1 | | | 10843 (100)| | | | | 0 |00:00:04.33 | 2447 | 0 | | | |
| 1 | MERGE | CO_S_ORDER_TEST | 1 | | | | | | | | 0 |00:00:04.33 | 2447 | 0 | | | |
| 2 | VIEW | | 1 | | | | | | | | 3799 |00:00:04.29 | 796 | 0 | | | |
| 3 | SEQUENCE | SEQ_CO_S_ORDER | 1 | | | | | | | | 3799 |00:00:04.29 | 796 | 0 | | | |
| 4 | PX COORDINATOR | | 1 | | | | | | | | 3799 |00:00:04.28 | 36 | 0 | | | |
| 5 | PX SEND QC (RANDOM) | :TQ10005 | 0 | 241 | 2353K| 10843 (44)| 00:00:02 | Q1,05 | P->S | QC (RAND) | 0 |00:00:00.01 | 0 | 0 | | | |
|* 6 | HASH JOIN OUTER BUFFERED | | 4 | 241 | 2353K| 10843 (44)| 00:00:02 | Q1,05 | PCWP | | 3799 |00:00:11.51 | 0 | 0 | 3418K| 1207K| 4/0/0|
| 7 | PX RECEIVE | | 4 | 241 | 2248K| 6095 (50)| 00:00:01 | Q1,05 | PCWP | | 3799 |00:00:00.01 | 0 | 0 | | | |
| 8 | PX SEND HASH | :TQ10003 | 0 | 241 | 2248K| 6095 (50)| 00:00:01 | Q1,03 | P->P | HASH | 0 |00:00:00.01 | 0 | 0 | | | |
|* 9 | VIEW | | 4 | 241 | 2248K| 6095 (50)| 00:00:01 | Q1,03 | PCWP | | 3799 |00:00:00.04 | 0 | 0 | | | |
| 10 | WINDOW SORT | | 4 | 241 | 727K| 6095 (50)| 00:00:01 | Q1,03 | PCWP | | 3799 |00:00:00.04 | 0 | 0 | 3046K| 544K| 4/0/0|
| 11 | PX RECEIVE | | 4 | 241 | 727K| 6095 (50)| 00:00:01 | Q1,03 | PCWP | | 3799 |00:00:00.01 | 0 | 0 | | | |
| 12 | PX SEND HASH | :TQ10002 | 0 | 241 | 727K| 6095 (50)| 00:00:01 | Q1,02 | P->P | HASH | 0 |00:00:00.01 | 0 | 0 | | | |
|* 13 | FILTER | | 4 | | | | | Q1,02 | PCWC | | 3799 |00:00:00.07 | 0 | 0 | | | |
| 14 | HASH GROUP BY | | 4 | 241 | 727K| 6095 (50)| 00:00:01 | Q1,02 | PCWP | | 4300 |00:00:00.07 | 0 | 0 | 22M| 2073K| 4/0/0|
| 15 | PX RECEIVE | | 4 | 241 | 727K| 6095 (50)| 00:00:01 | Q1,02 | PCWP | | 4654 |00:00:00.04 | 0 | 0 | | | |
| 16 | PX SEND HASH | :TQ10001 | 0 | 241 | 727K| 6095 (50)| 00:00:01 | Q1,01 | P->P | HASH | 0 |00:00:00.01 | 0 | 0 | | | |
| 17 | HASH GROUP BY | | 4 | 241 | 727K| 6095 (50)| 00:00:01 | Q1,01 | PCWP | | 4654 |00:00:03.41 | 100K| 99050 | 35M| 4145K| 4/0/0|
| 18 | VIEW | | 4 | 4801 | 14M| 6093 (50)| 00:00:01 | Q1,01 | PCWP | | 4801 |00:00:00.77 | 100K| 99050 | | | |
| 19 | UNION-ALL | | 4 | | | | | Q1,01 | PCWP | | 4801 |00:00:00.77 | 100K| 99050 | | | |
| 20 | PX BLOCK ITERATOR | | 4 | 3120 | 1523K| 4 (0)| 00:00:01 | Q1,01 | PCWC | | 3120 |00:00:00.01 | 290 | 0 | | | |
|* 21 | TABLE ACCESS FULL | STG_S_ORDER_DELTA | 58 | 3120 | 1523K| 4 (0)| 00:00:01 | Q1,01 | PCWP | | 3120 |00:00:00.01 | 290 | 0 | | | |
|* 22 | HASH JOIN RIGHT SEMI | | 4 | 4152 | 1857K| 6088 (50)| 00:00:01 | Q1,01 | PCWP | | 1681 |00:00:04.41 | 99890 | 99050 | 1295K| 1295K| 4/0/0|
| 23 | PX RECEIVE | | 4 | 3120 | 31200 | 4 (0)| 00:00:01 | Q1,01 | PCWP | | 12480 |00:00:00.02 | 0 | 0 | | | |
| 24 | PX SEND BROADCAST | :TQ10000 | 0 | 3120 | 31200 | 4 (0)| 00:00:01 | Q1,00 | P->P | BROADCAST | 0 |00:00:00.01 | 0 | 0 | | | |
| 25 | PX BLOCK ITERATOR | | 4 | 3120 | 31200 | 4 (0)| 00:00:01 | Q1,00 | PCWC | | 3120 |00:00:00.01 | 290 | 0 | | | |
|* 26 | TABLE ACCESS FULL| STG_S_ORDER_DELTA | 58 | 3120 | 31200 | 4 (0)| 00:00:01 | Q1,00 | PCWP | | 3120 |00:00:00.01 | 290 | 0 | | | |
| 27 | PX BLOCK ITERATOR | | 4 | 4135K| 1766M| 6048 (50)| 00:00:01 | Q1,01 | PCWC | | 3710K|00:00:03.26 | 99890 | 99050 | | | |
|* 28 | TABLE ACCESS FULL | CO_S_ORDER_TEST | 84 | 4135K| 1766M| 6048 (50)| 00:00:01 | Q1,01 | PCWP | | 3710K|00:00:02.92 | 99890 | 99050 | | | |
| 29 | PX RECEIVE | | 4 | 6107K| 2609M| 4694 (35)| 00:00:01 | Q1,05 | PCWP | | 6107K|00:00:11.11 | 0 | 0 | | | |
| 30 | PX SEND HASH | :TQ10004 | 0 | 6107K| 2609M| 4694 (35)| 00:00:01 | Q1,04 | P->P | HASH | 0 |00:00:00.01 | 0 | 0 | | | |
| 31 | PX BLOCK ITERATOR | | 4 | 6107K| 2609M| 4694 (35)| 00:00:01 | Q1,04 | PCWC | | 6107K|00:00:05.37 | 99890 | 99050 | | | |
|* 32 | TABLE ACCESS FULL | CO_S_ORDER_TEST | 84 | 6107K| 2609M| 4694 (35)| 00:00:01 | Q1,04 | PCWP | | 6107K|00:00:04.69 | 99890 | 99050 | | | |
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Listing 1 Execution Plan using GROUP BY with pre-filter
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows |E-Bytes|E-Temp | Cost (%CPU)| E-Time | TQ |IN-OUT| PQ Distrib | A-Rows | A-Time | Buffers | Reads | Writes | OMem | 1Mem | O/1/M | Max-Tmp | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | 0 | MERGE STATEMENT | | 1 | | | | 221K(100)| | | | | 0 |00:05:46.11 | 2447 | 0 | 0 | | | | | | 1 | MERGE | CO_S_ORDER_TEST | 1 | | | | | | | | | 0 |00:05:46.11 | 2447 | 0 | 0 | | | | | | 2 | VIEW | | 1 | | | | | | | | | 3799 |00:05:45.89 | 797 | 0 | 0 | | | | | | 3 | SEQUENCE | SEQ_CO_S_ORDER | 1 | | | | | | | | | 3799 |00:05:45.89 | 797 | 0 | 0 | | | | | | 4 | PX COORDINATOR | | 1 | | | | | | | | | 3799 |00:05:45.88 | 37 | 0 | 0 | | | | | | 5 | PX SEND QC (RANDOM) | :TQ10003 | 0 | 7422K| 69G| | 221K (3)| 00:00:35 | Q1,03 | P->S | QC (RAND) | 0 |00:00:00.01 | 0 | 0 | 0 | | | | | |* 6 | HASH JOIN RIGHT OUTER BUFFERED| | 16 | 7422K| 69G| | 221K (3)| 00:00:35 | Q1,03 | PCWP | | 3799 |00:15:42.85 | 0 | 71 | 71 | 2047M| 33M| 16/0/0| 1024 | | 7 | PX RECEIVE | | 16 | 6107K| 2609M| | 1174 (35)| 00:00:01 | Q1,03 | PCWP | | 6107K|00:01:42.93 | 0 | 0 | 0 | | | | | | 8 | PX SEND HASH | :TQ10001 | 0 | 6107K| 2609M| | 1174 (35)| 00:00:01 | Q1,01 | P->P | HASH | 0 |00:00:00.01 | 0 | 0 | 0 | | | | | | 9 | PX BLOCK ITERATOR | | 16 | 6107K| 2609M| | 1174 (35)| 00:00:01 | Q1,01 | PCWC | | 6107K|00:00:05.42 | 101K| 99050 | 0 | | | | | |* 10 | TABLE ACCESS FULL | CO_S_ORDER_TEST | 251 | 6107K| 2609M| | 1174 (35)| 00:00:01 | Q1,01 | PCWP | | 6107K|00:00:04.86 | 101K| 99050 | 0 | | | | | | 11 | PX RECEIVE | | 16 | 7422K| 66G| | 219K (3)| 00:00:35 | Q1,03 | PCWP | | 3799 |00:08:25.26 | 0 | 0 | 0 | | | | | | 12 | PX SEND HASH | :TQ10002 | 0 | 7422K| 66G| | 219K (3)| 00:00:35 | Q1,02 | P->P | HASH | 0 |00:00:00.01 | 0 | 0 | 0 | | | | | |* 13 | VIEW | | 16 | 7422K| 66G| | 219K (3)| 00:00:35 | Q1,02 | PCWP | | 3799 |01:08:17.83 | 823 | 1127K| 1127K| | | | | | 14 | WINDOW SORT | | 16 | 7422K| 21G| 25G| 219K (3)| 00:00:35 | Q1,02 | PCWP | | 7422K|01:23:52.70 | 823 | 1127K| 1127K| 10G| 24M| 4/12/0| 591K| | 15 | WINDOW SORT | | 16 | 7422K| 21G| 25G| 219K (3)| 00:00:35 | Q1,02 | PCWP | | 7422K|00:52:43.97 | 754 | 601K| 601K| 10G| 24M| | 615K| | 16 | PX RECEIVE | | 16 | 7422K| 21G| | 2188 (45)| 00:00:01 | Q1,02 | PCWP | | 7422K|00:11:15.00 | 0 | 0 | 0 | | | | | | 17 | PX SEND HASH | :TQ10000 | 0 | 7422K| 21G| | 2188 (45)| 00:00:01 | Q1,00 | P->P | HASH | 0 |00:00:00.01 | 0 | 0 | 0 | | | | | | 18 | VIEW | | 16 | 7422K| 21G| | 2188 (45)| 00:00:01 | Q1,00 | PCWP | | 7422K|00:01:03.91 | 161K| 156K| 0 | | | | | | 19 | UNION-ALL | | 16 | | | | | | Q1,00 | PCWP | | 7422K|00:00:52.98 | 161K| 156K| 0 | | | | | | 20 | PX BLOCK ITERATOR | | 16 | 3710K| 1525M| | 676 (36)| 00:00:01 | Q1,00 | PCWC | | 3712K|00:00:24.22 | 59203 | 57097 | 0 | | | | | |* 21 | TABLE ACCESS FULL | STG_S_ORDER_FULL | 234 | 3710K| 1525M| | 676 (36)| 00:00:01 | Q1,00 | PCWP | | 3712K|00:00:24.75 | 59203 | 57097 | 0 | | | | | | 22 | PX BLOCK ITERATOR | | 16 | 4135K| 1766M| | 1512 (50)| 00:00:01 | Q1,00 | PCWC | | 3710K|00:00:22.72 | 101K| 99050 | 0 | | | | | |* 23 | TABLE ACCESS FULL | CO_S_ORDER_TEST | 251 | 4135K| 1766M| | 1512 (50)| 00:00:01 | Q1,00 | PCWP | | 3710K|00:00:22.19 | 101K| 99050 | 0 | | | | | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Listing 2 Execution Plan using analytic function with pre-filter
Test case #2
In the first test case the source of the ETL process was the staging table. What if we were loading a dimension table from the huge table in the EDW or using a view? The benefit of not reading a huge table or doing a complex logic of the view twice can outweigh the performance loss even without a pre-filter. In my test case some „big“ tables (50 Gb, 40+ Mio rows) are joined via a view and produce about 500 dimension records per day. The loading time could be reduced by 45 percent (3 min 50 sec → 2 min).
Conclusion
Actually I find the proposed way a simple alternative that is worth further testing. But not for every use case. In my opinion the development of the real-life data warehouse systems should be highly automated and some kind of generator/automation tools should be used, e.g. biGENiUS, which handle the whole complexity of a change detection. If you are indeed doing the whole work manually, you can consider this “new” way altogether and benefit from its simplicity in the development and maintenance.