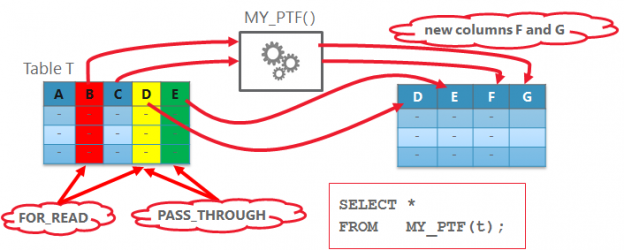
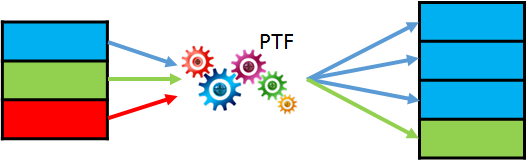
In the third part of the PTF-series we learn how a PTF can change the cardinality of the input data flow: return more or less rows as in the input. We’ll use the same simple table as in the part 2 and our new task will be column transposing. We’ll still define, which columns have to stay unchanged (as we already did using the parameter cols2stay). All other columns should be displayed as key-value pairs. Continue reading
Polymorphic Table Functions (PTF) , Part 3 – Row Replication
5 Replies