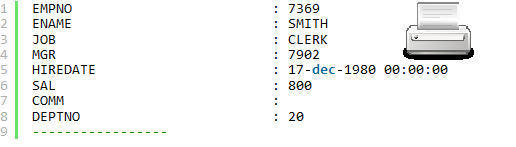
In my very first post about SQL macros, I mentioned that for table macros, there is a simple way to see the SQL statement after macro expansion using dbms_utility.expand_sql_text. However, for scalar SQL macros, there is no such straightforward method. We can activate a CBO trace (also known as event 10053) and find the final statement in the trace file. This approach works for both scalar and table SQL macros. In this post, we will explore how to do this, and we will use… a SQL macro for that! Well, at least we will give it a try…
Continue reading →