
Die Historisierung der Daten ist eine typische aber auch rechen- und zeitintensive Aufgabe im Data Warehouse Umfeld. Man hat damit beim Beladen von historisierter Core-Schicht (auch bekannt als Enterprise Data Warehouse or Foundation Layer), Data Vault Datenmodellen, Slowly Changing Dimensions, etc. zu tun. Typische Methoden führen einen Outer Join und eine Art der Deltaerkennung aus. Diese Deltaerkennung ist wohl der kniffligste Teil, denn man muss die Null-Werte besonders beachten. Eine sehr gute Übersicht der verwendeten Techniken hat Dani Schnider in seinem Blog zusammengestellt: Delta Detection in Oracle SQL
Auf der anderen Seite bietet die SQL-Standardfunktionalität genau das Verhalten an, das hier gebraucht wird: die Group By Klausel oder Partitioning-Klausel bei analytischen Funktionen. Kann man das ausnutzen? Macht es Sinn? Wie wird dann der ETL Prozess aussehen? Können wir eventuell das Laden durch Partition Exchange weiter beschleunigen? Ich werde diese Fragen in den nächsten Beiträgen beleuchten.
Einführung und die typische Vorgehensweise
Ich nehme an, dass Ihnen die grundsätzlichen Konzepte für die Historisierung und temporale Gültigkeit der Daten bekannt sind. Wir betrachten den Historisierungsprinzip, den man als „Slowly Changing Dimensions Type 2“ kennt. Der Name soll Sie aber nicht irritieren: es geht hier nicht nur um die Dimensionen.
Schauen wir uns folgendes Beispiel an. Eine Quelltabelle wird täglich in eine Zieltabelle ins Datawarehouse System geladen. Die Zieltabelle hat Datumsspalten für die Gültigkeitsangaben und erlaubt mehrere Versionen pro Business Key. Wenn wir für einen Business Key an einem Ladetag Änderungen in den gelieferten Daten feststellen, schliessen wir die aktuelle Version ab (setzen das gültig_bis Datum) und legen eine neue Version an. Keine Daten werden überschrieben und alle Änderungen sind über den gesamten Zeitraum nachvollziehbar.
whenever sqlerror continue
drop table t_source purge;
drop table t_target purge;
drop sequence scd2_seq ;
create sequence scd2_seq ;
--Source Table
create table t_source
( load_date date
, business_key varchar2(5)
, first_name varchar2(50)
, second_names varchar2(100)
, last_name varchar(50)
, hire_date date
, fire_date date
, salary number(10));
-- Target Table
create table t_target
( dwh_key number
, dwh_valid_from date
, dwh_valid_to date
, current_version char(1 byte)
, etl_op varchar2(3 byte)
, business_key varchar2(5)
, first_name varchar2(50)
, second_names varchar2(100)
, last_name varchar(50)
, hire_date date
, fire_date date
, salary number(10));
insert into t_source (load_date, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(DATE '2016-12-01', '123', 'Roger', null, 'Federer', DATE '2010-01-01', null, 900000);
insert into t_source (load_date, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(DATE '2016-12-01', '456', 'Rafael', null, 'Nadal', DATE '2009-05-01', null, 720000);
insert into t_source (load_date, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(DATE '2016-12-01', '789', 'Serena', null, 'Williams', DATE '2008-06-01', null, 650000);
-- We simulate the first ETL run and simply insert our data in the target table
insert into t_target (dwh_key, dwh_valid_from, dwh_valid_to, current_version, etl_op, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(scd2_seq.nextval, DATE '2016-12-01', null, 'Y', 'INS', '123', 'Roger', null, 'Federer', DATE '2010-01-01', null, 900000);
insert into t_target (dwh_key, dwh_valid_from, dwh_valid_to, current_version, etl_op, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(scd2_seq.nextval, DATE '2016-12-01', null, 'Y', 'INS', '456', 'Rafael', null, 'Nadal', DATE '2009-05-01', null, 720000);
insert into t_target (dwh_key, dwh_valid_from, dwh_valid_to, current_version, etl_op, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(scd2_seq.nextval, DATE '2016-12-01', null, 'Y', 'INS', '789', 'Serena', null, 'Williams', DATE '2008-06-01', null, 650000);
commit;
Der meist verbreitete Ansatz, den ich gesehen habe, fängt mit einem Outer Join von der Quelltabelle mit den aktuellen Versionen aus der Zieltabelle an. Der Join wird über den Business Key gemacht. Wenn wir im Join-Ergebnis den Business Key nur auf einer Seite des Joins haben, bedeutet das, dass wir mit neuen oder gelöschten Datensätzen zu tun haben. Wenn der Key auf beiden Seiten vorhanden ist, müssen wir die tatsächlichen Änderungen weiter untersuchen. Damit die alten Versionen geschlossen und die neuen Versionen in einem MERGE Statement angelegt werden können, müssen wir das Ergebnis vom Join wieder in zwei „Töpfe“ verteilen (splitten) und anschließend mit einem UNION ALL wieder zusammenführen. Der Ansatz ist im oben erwähnten Blog-Beitrag sehr gut beschrieben: Delta Detection in Oracle SQL
Das typische Muster vom ETL-Prozess sieht in Oracle Warehouse Builder etwa so aus:
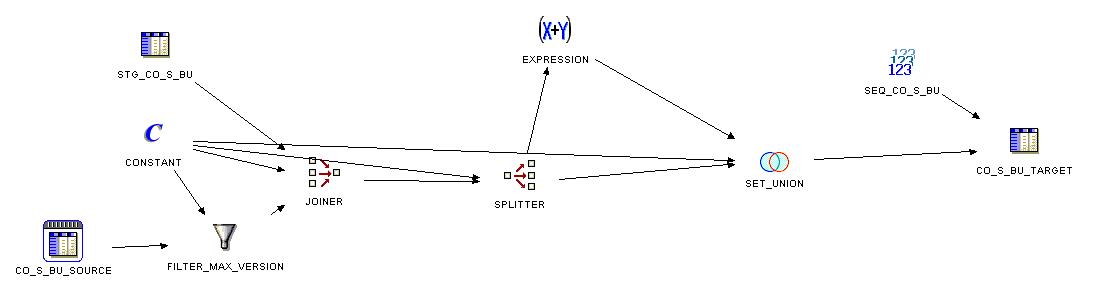
Ziemlich viel Arbeit! Der weitere Nachteil der OWB-Implementierung liegt darin, dass die Quelle und das Ziel zwei Mal gescnaned und gejoined werden. Also, können wir das besser machen?
Der Ansatz
Stellen wir vor, am nächsten Tag kommen neue Daten in der Quelle an:
-- Next we get new data in the source
delete from t_source;
insert into t_source (load_date, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(DATE '2016-12-02', '123', 'Roger', null, 'Federer', DATE '2010-01-01', null, 900000);
insert into t_source (load_date, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(DATE '2016-12-02', '456', 'Rafael', null, 'Nadal', DATE '2009-05-01', null, 720000);
-- New Second_name
insert into t_source (load_date, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(DATE '2016-12-02', '789', 'Serena', 'Jameka', 'Williams', DATE '2008-06-01', null, 650000);
--new record
insert into t_source (load_date, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(DATE '2016-12-02', '345', 'Venus', null, 'Williams', DATE '2016-11-01', null, 500000);
commit;
Für den Business Key 789 (Serena Williams) bekommen wir den zweiten Namen statt eines Null-Wertes. Der Business Key 345 (Venus Williams) ist neu.
Nun haben wir folgenden Inhalt in unseren beiden Tabellen:
select * from t_source;
LOAD_DATE BUS FIRST_NAME SECOND_NAM LAST_NAME HIRE_DATE FIRE_DATE SALARY
---------- --- ---------- ---------- ---------- ---------- ---------- ----------
2016-12-02 123 Roger Federer 2010-01-01 900000
2016-12-02 456 Rafael Nadal 2009-05-01 720000
2016-12-02 789 Serena Jameka Williams 2008-06-01 650000
2016-12-02 345 Venus Williams 2016-11-01 500000
4 rows selected.
select * from t_target;
DWH_KEY DWH_VALID_ DWH_VALID_ C ETL_OP BUS FIRST_NAME SECOND_NAM LAST_NAME HIRE_DATE FIRE_DATE SALARY
---------- ---------- ---------- - ------ --- ---------- ---------- ---------- ---------- ---------- ----------
1 2016-12-01 Y INS 123 Roger Federer 2010-01-01 900000
2 2016-12-01 Y INS 456 Rafael Nadal 2009-05-01 720000
3 2016-12-01 Y INS 789 Serena Williams 2008-06-01 650000
3 rows selected.
Schritt 1
Wir müssen nun die Daten in der Quelltabelle mit den aktuellen Versionen aus der Zieltabelle vergleichen, pro Business Key vertsteht sich. Vielleicht ist es auf den ersten Blick nicht nachvollziehbar, aber statt diese zu joinen, führen wir diese Daten einmal mit einem UNION ALL Operator zusammen:
-- The current versions in the target table select 'T' source_target -- to distinguish these records later , business_key , dwh_valid_from , first_name , second_names , last_name , hire_date , fire_date , salary from t_target where current_version = 'Y' -- Now the new data -- put them together with UNION ALL union all select 'S' source_target , business_key , load_date dwh_valid_from -- we use load_date as the new validity start date , first_name , second_names , last_name , hire_date , fire_date , salary from t_source; S BUS DWH_VALID_ FIRST_NAME SECOND_NAM LAST_NAME HIRE_DATE FIRE_DATE SALARY - --- ---------- ---------- ---------- ---------- ---------- ---------- ---------- T 123 2016-12-01 Roger Federer 2010-01-01 900000 T 456 2016-12-01 Rafael Nadal 2009-05-01 720000 T 789 2016-12-01 Serena Williams 2008-06-01 650000 S 123 2016-12-02 Roger Federer 2010-01-01 900000 S 456 2016-12-02 Rafael Nadal 2009-05-01 720000 S 789 2016-12-02 Serena Jameka Williams 2008-06-01 650000 S 345 2016-12-02 Venus Williams 2016-11-01 500000 7 rows selected.
Damit wir dann im Ergebnis zwischen den Datensätzen aus der Quell- und aus der Zieltabelle unterscheiden können, führen wir eine Spalte SOURCE_TARGET ein, die die Werte ‚T‘ wie Target und ‚S‘ wie Source annehmen kann.
Im Union-Ergebnis können wir maximal zwei Datensätze pro Business Key haben. Die möglichen Konstellationen sind:
- Die untersuchten Spalten in beiden Datensätzen sind exakt gleich – keine Aktion notwendig
- Die untersuchten Spalten wurden geändert – das müssen wir erkenne, eine Version abschliessen und eine andere neu anlegen
- Es gibt nur einen Datensatz pro Business Key, und zwar wenn ein neuer Datensatz kommt, für den es noch gar keine Version in der Zieltabelle existiert oder wenn ein Datensatz aus der Quelle gelöscht wird
Schritt 2
Dann zählen wir einfach die Datensätze pro Business Key und Spalten, die wir „beobachten“, mit Hilfe der analytischen Funktion count(). Das Interessante passiert in der Zeile 32. Die Partioning-Klausel ist hier der Business_key und alle Spalten, die wir auf Änderungen untersuchen. Diese Klausel macht die ganze Arbeit für die Deltarerkennung für uns. Ihr Verhalten ist genau das, was wir brauchen: NULL=NULL und NULL!=WERT. Wenn etwas geändert wurde (auch von NULL auf einen Wert oder von einem Wert auf NULL), bekommen wir eine neue Partition innerhalb der analytischen Funktion. Gab es keine Änderung, sind der neue und der alte Datensatz in derselben Partition.
with union_source_target as ( -- What are the current versions in the target table select 'T' source_target -- to distinguish these records later , business_key , dwh_valid_from , first_name , second_names , last_name , hire_date , fire_date , salary from t_target where current_version = 'Y' -- Now the new data -- put them together with UNION ALL union all select 'S' source_target , business_key , load_date dwh_valid_from -- we use load_date as the new validity start date , first_name , second_names , last_name , hire_date , fire_date , salary from t_source ) select un.* -- we need NVL for the records which were deleted in source in case we must "close" them. The constant means for example load date and can be returned from PL/SQL function , nvl(lead (dwh_valid_from ) over(partition by business_key order by dwh_valid_from) - 1, DATE '2016-12-02' ) new_dwh_valid_to , count(*) over (partition by business_key, first_name, second_names, last_name, hire_date, fire_date, salary) cnt -- cnt = 2 - two versions are the same, otherwise INS/UPD/DEL , count(*) over (partition by business_key) cnt_key -- the count of versions per business_key from union_source_target un;
Schritt 3
Wie können wir die im Schritt 2 gewonnenen Informationen weiter nutzen? Wenn die Anzahl gleich zwei ist, haben wir zwei gleiche Datensätze und müssen nichts machen. Ansonsten müssen wir Insert, Update or Delete verarbeiten. Wir können nun die erwartetetn Aktionen mit Hilfe folgender Abfrage anzeigen, nur damit man sieht, was passieren wird.
-- Filter only the records where some action is needed and show what kind of action
with union_source_target as
(
-- What are the current versions in the target table
select 'T' source_target -- to distinguish these records later
, business_key
, dwh_valid_from
, first_name
, second_names
, last_name
, hire_date
, fire_date
, salary
from t_target
where current_version = 'Y'
-- Now the new data
-- put them together with UNION ALL
union all
select 'S' source_target
, business_key
, load_date dwh_valid_from -- we use load_date as the new validity start date
, first_name
, second_names
, last_name
, hire_date
, fire_date
, salary
from t_source
)
, action_needed as
(
select un.*
-- we need NVL for the records which were deleted in source in case we must "close" them. The constant means for example load date and can be returned from PL/SQL function
, nvl(lead (dwh_valid_from ) over(partition by business_key order by dwh_valid_from) - 1, DATE '2016-12-02' ) new_dwh_valid_to
, count(*) over (partition by business_key, first_name, second_names, last_name, hire_date, fire_date, salary) cnt -- cnt = 2 - two versions are the same, otherwise INS/UPD/DEL
, count(*) over (partition by business_key) cnt_key -- the count of versions per business_key (in this result set only, not in the target table)
from union_source_target un
)
select an.*
, case
when source_target = 'T' and cnt_key > 1 then 'Close this version (new version will be added)'
when source_target = 'T' and cnt_key = 1 then 'Close this version (no new version will be added, the record was deleted in source)'
when source_target = 'S' then 'Insert new version'
end action
from action_needed an
where cnt != 2
S BUS DWH_VALID_ FIRST_NAME SECOND_NAM LAST_NAME HIRE_DATE FIRE_DATE SALARY NEW_DWH_VALID_TO CNT CNT_KEY ACTION
- --- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ---------------- --- ------- --------------------------------------------------
S 345 2016-12-02 Venus Williams 2016-11-01 500000 2016-12-02 1 1 Insert new version
T 789 2016-12-01 Serena Williams 2008-06-01 650000 2016-12-01 1 2 Close this version (new version will be added)
S 789 2016-12-02 Serena Jameka Williams 2008-06-01 650000 2016-12-02 1 2 Insert new version
3 rows selected.
Schritt 4
Alle Aktionen sind wie erwartet und wir können dieses Zwischenergebnis mit einem MERGE-Befehl mit der Zieltabelle zusammenführen:
merge into t_target t
using (
with union_source_target as
(
-- What are the current versions in the target table
select 'T' source_target -- to distinguish these records later
, business_key
, dwh_valid_from
, first_name
, second_names
, last_name
, hire_date
, fire_date
, salary
from t_target
where current_version = 'Y'
-- Now the new data
-- put them together with UNION ALL
union all
select 'S' source_target
, business_key
, load_date dwh_valid_from -- we use load_date as the new validity start date
, first_name
, second_names
, last_name
, hire_date
, fire_date
, salary
from t_source
)
, action_needed as
(
select un.*
-- we need NVL for the records which were deleted in source in case we must "close" them. The constant means for example load date and can be returned from PL/SQL function
, nvl(lead (dwh_valid_from ) over(partition by business_key order by dwh_valid_from) - 1, DATE '2016-12-02' ) new_dwh_valid_to
, count(*) over (partition by business_key, first_name, second_names, last_name, hire_date, fire_date, salary) cnt -- cnt = 2 - two versions are the same, otherwise INS/UPD/DEL
, count(*) over (partition by business_key) cnt_key -- the count of versions per business_key (in this result set only, not in the target table)
from union_source_target un
)
select an.*
, case
when source_target = 'T' and cnt_key > 1 then 'Close this version (new version will be added)'
when source_target = 'T' and cnt_key = 1 then 'Close this version (no new version will be added, the record was deleted in source)'
when source_target = 'S' then 'Insert new version'
end action
from action_needed an
where cnt != 2
) q
on ( t.business_key = q.business_key and t.dwh_valid_from = q.dwh_valid_from )
when not matched then insert ( dwh_key
, dwh_valid_from
, dwh_valid_to
, current_version
, etl_op
, business_key
, first_name
, second_names
, last_name
, hire_date
, fire_date
, salary )
values ( scd2_seq.nextval
, q.dwh_valid_from
, NULL -- NULL means no end date
, 'Y'
, 'INS'
, q.business_key
, q.first_name
, q.second_names
, q.last_name
, q.hire_date
, q.fire_date
, q.salary )
when matched then update set
t.dwh_valid_to = q.new_dwh_valid_to
, t.current_version = 'N'
, t.etl_op = 'UPD';
Fertig! Was ist in der Zieltabelle nach dem MERGE? Genau das, was wir erwarten: eine neue Version für Venus Williams und auch für Serena Williams. Beide sind ab dem 2016-12-02, unserem Ladedatum, gültig. Die alte Version für Serena Williams wurde geschlossen mit „gültig bis“ Datum von 2016-12-01.
select *
from t_target
order by business_key, dwh_valid_from;
DWH_KEY DWH_VALID_ DWH_VALID_ C ETL_OP BUS FIRST_NAME SECOND_NAM LAST_NAME HIRE_DATE FIRE_DATE SALARY
---------- ---------- ---------- - ------ --- ---------- ---------- ---------- ---------- ---------- ----------
1 2016-12-01 Y INS 123 Roger Federer 2010-01-01 900000
6 2016-12-02 Y INS 345 Venus Williams 2016-11-01 500000
2 2016-12-01 Y INS 456 Rafael Nadal 2009-05-01 720000
3 2016-12-01 2016-12-01 N UPD 789 Serena Williams 2008-06-01 650000
5 2016-12-02 Y INS 789 Serena Jameka Williams 2008-06-01 650000
5 rows selected.
Noch ein Test, das nächste Ladedatum ist 2016-12-03. We ändern die numerische Spalte SALARY, Datumsspalte FIRE_DATE und löschen den Datensatz von Rafael Nadal aus der Quelle:
delete from t_source;
-- Salary changed
insert into t_source (load_date, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(DATE '2016-12-03', '123', 'Roger', null, 'Federer', DATE '2010-01-01', null, 920000);
-- Business_key = 456 is not there anymore
-- No change
insert into t_source (load_date, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(DATE '2016-12-03', '789', 'Serena', 'Jameka', 'Williams', DATE '2008-06-01', null, 650000);
-- Change in fire_date
insert into t_source (load_date, business_key, first_name, second_names, last_name, hire_date, fire_date, salary)
values(DATE '2016-12-03', '345', 'Venus', null, 'Williams', DATE '2016-11-01', DATE '2016-12-01', 500000);
commit;
MERGE
...
select *
from t_target
order by business_key, dwh_valid_from;
DWH_KEY DWH_VALID_ DWH_VALID_ C ETL_OP BUS FIRST_NAME SECOND_NAM LAST_NAME HIRE_DATE FIRE_DATE SALARY
---------- ---------- ---------- - ------ --- ---------- ---------- ---------- ---------- ---------- ----------
1 2016-12-01 2016-12-02 N UPD 123 Roger Federer 2010-01-01 900000
11 2016-12-03 Y INS 123 Roger Federer 2010-01-01 920000
6 2016-12-02 2016-12-02 N UPD 345 Venus Williams 2016-11-01 500000
10 2016-12-03 Y INS 345 Venus Williams 2016-11-01 2016-12-01 500000
2 2016-12-01 2016-12-02 N UPD 456 Rafael Nadal 2009-05-01 720000
3 2016-12-01 2016-12-01 N UPD 789 Serena Williams 2008-06-01 650000
5 2016-12-02 Y INS 789 Serena Jameka Williams 2008-06-01 650000
7 rows selected.
Wie man sieht, hat Roger Federer eine Gehaltserhöhung sowie eine neue Version bekommen, Venus Willaims wurde gefeuert und hat auch nun eine neue Version. Der Datensatz für Rafael Nadal wurde in der Quelle gelöscht. Das haben wir erkannt und in der Zieltabelle entsprechend das „gültig bis“ Datum gesetzt.
Man kann natürlich darüber diskutieren, was die richtige Strategie im Umgang mit zeitlicher Gültigkeit ist. Wie definiere ich Unendlichkeit, mit Null-Werten, wie im Beispiel, oder mit speziellen Werten wie 31. Dezember 9999? Macht es Sinn, die aktuellen Versionen mit einem Kennzeichen zu versehen, z.B. current_version (Yes/No)? Ist es besser, wenn Gültig_bis Datum und Gültig_von vom der darauffolgender Version gleich sind oder wenn dazwischen ein Tag liegt? Was ist die beste Strategie im Umgang mit gelöschten Datensätzen? Natürlich sind diese Fragen alle berechtigt, sie stehen aber hier nicht im Mittelpunkt. Mit diesem Ansatz haben wir ausreichend Informationen, um beliebige Strategie implementieren zu können.
Fazit
Das ganze sieht ziemlich einfach aus, macht aber was wir brauchen! Wie vermeiden den (Outer) Join. Wir vermeiden die komplexe Deltaerkennung mit NVL, Hash-Werten o.ä. Die Quelle wird nur einmal gescannt, was insbesondere dann wichtig ist, wenn als Quelle komplexe Views agieren. Noch besser, weil wir anstelle des Joins einen UNION ALL haben – in 12c werden beide Zweige eines UNION Operators nicht nacheinander, sondern gleichzeitig ausgeführt. Das alles klingt für mich vielversprechend.
Ich bleibe dran und forsche weiter, vergleiche die Perormance, wie läuft die Abfrage in parallel usw. Werde die Ergebnisse hier präsentieren. Ist es möglich, das Statement so anzupassen, dass auch die SCD1-Spalten direkt mitberücksichtigt werden können? Eine andere intersessante Möglichkeit, die ich bereits getestet habe und die auch auf derselben Grundidee basiert, wäre ein Multi-Table Insert statt MERGE mit anschliessendem Partition Exchange. Ich beschreibe das in einem der nächsten Beiträge.