
It was not possible for me to write a follow-up to my last post about Transposing Columns To Rows with PTF showing an opposite task of transposing rows to columns right next weekend as I thought. Partly because of our awesome Trivadis TechEvent which took place back then and partly because this kind of the exercise turned out to be much more difficult one as supposed. Actually it is a nice example to see the limitations of the new feature.
I also realized that it was probably not a good idea to start to write about PTF with these two examples going too deep in the detail. That’s why I plan to write some step-by-step posts on PTF.
But for now, let’s stay with the example. What we achieved in the previous post? We transposed the columns of the SCOTT.EMP table into rows, so that the result set looked like this:
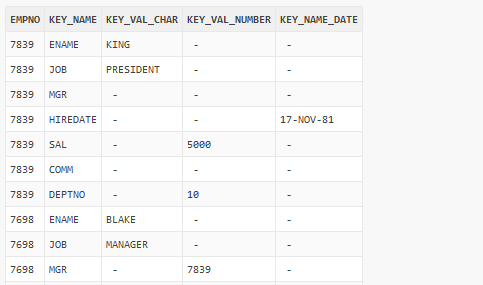
Figure 1
The problem
Now we want to query this structure and get the result set in a form like the original SCOTT.EMP had. What is the problem here? Assume that we don’t know the structure of SCOTT.EMP, and we need to reproduce it based on the pictured data set. Yes, we could do this, but only by looking at the data itself. For example, we need to query all rows for the EMPNO=7839 and then we know, there are seven columns in addition to EMPNO and what their data types are (based on NOT NULL values in corresponding columns). If these can vary from EMPNO to EMPNO, then we need to query the whole data set to determine the final output structure.
On the other hand, what degree of flexibility the polymorphic functions are providing? At design time we don’t need to know the shape of the input table and don’t have to determine the shape of the return type. The return type is determined by the PTF invocation arguments list. Now we have two phases: SQL cursor compilation and execution. During the compilation the function DESCRIBE is called and that is the point where the return type must be determined. We cannot change the shape of the result set during the execution.
So we are not flexible enough to do this. Can we work around this? What if we could query the source data set inside the DESCRIBE function and thus would be able to determine the structure? Of course, that means we would dramatically increase the parse time, possibly reading the whole data before the execution even starts. But let’s try.
If I want to know what keys with their respective data types are stored in the table T, I would possibly use some query like this:
SELECT DISTINCT
key_name
, first_value(datatype) OVER (PARTITION BY key_name
ORDER BY rnk DESC) datatype
FROM (SELECT key_name
, CASE
WHEN key_val_char IS NOT NULL THEN 'C'
WHEN key_val_date IS NOT NULL THEN 'D'
WHEN key_val_number IS NOT NULL THEN 'N'
ELSE 'C'
END datatype
, CASE
WHEN key_val_char IS NULL
AND key_val_date IS NULL
AND key_val_number IS NULL
THEN 0
ELSE 1
END rnk
FROM t);
KEY_NAME D
------------------------------ -
ENAME C
HIREDATE D
DEPTNO N
JOB C
SAL N
COMM N
MGR N
7 rows selected.
Listing 1
If there are rows where the value for the key is null like the key COMM for EMPNO=7839, you cannot definitely say what datatype the key has. I introduced the column RNK, to address this issue, so that the rows with values for particular key will be considered first. Of course this implementation is by no means complete and doesn’t handle all cases, e.g. what happens if values for the same key are stored differently, sometimes as number, sometimes as string? But I think, it is sufficient for our example.
Try to get the structure with a PTF
Let us first try to develop a PTF which returns exactly this information and postpone the task of pivoting the rows for a while.
We’ll implement the function GET_COLS which can be called as follows:
SELECT * FROM get_cols(t);
Listing 2
First create an implementation package for the function. What we need is the function DESCRIBE and the procedure FETCH_ROWS. We don’t need the optional OPEN and CLOSE procedures here. For this simple example we also don’t need the parameter of the type COLUMNS, since we are not going to define some logic based on the specified columns.
CREATE OR REPLACE PACKAGE get_cols_pkg AS
FUNCTION describe(tab IN OUT DBMS_TF.TABLE_T)
RETURN DBMS_TF.DESCRIBE_T;
PROCEDURE fetch_rows;
END get_cols_pkg;
/
Listing 3
And now the implementation along with some explanations.
Function DESCRIBE:
- Lines 14-17: We want two columns (COLUMN_NAME and DATATYPE) to be in the result set, so we need to define them using COLUMN_METADATA_T record type. The collection NEW_COLS will be returned out of the DESCRIBE function as a part of DESCRIBE_T record type (see the lines 54 and 57)
- Lines 20-23: All columns from the original table are not of interest: we just mark both properties PASS_THROUGH and FOR_READ as FALSE
- Lines 25-46: Define and execute a dynamic SQL statement to assess the existing key names and their data types
- Lines 48-52: Actually this information is already the answer to be returned from our PTF. We should save it until the execution phase using the “compilation store”
Procedure FETCH_ROWS:
- Line 71: Get input row set
- Lines 73-85: Until there are columns we have saved in the compilation store in the DESCRIBE function, fill the collections NAMECOL and TYPECOL if not yet done (check execution store at line 78). Suppress all other rows (line 74). Notice the processed column in the execution store (line 82).
- Line 87: Set the row replication with prepared collection REPFAC
- Lines 89-90: Put the collections with processed values in the output result set
CREATE OR REPLACE PACKAGE BODY get_cols_pkg AS
FUNCTION describe(tab IN OUT DBMS_TF.TABLE_T)
RETURN DBMS_TF.DESCRIBE_T
AS
new_cols DBMS_TF.COLUMNS_NEW_T;
col_id PLS_INTEGER := 1;
v_sql VARCHAR2(2000);
type t_colrec is record (column_name dbms_id, datatype varchar2(1));
type t_colrectab is table of t_colrec index by pls_integer;
v_colrectab t_colrectab;
descr DBMS_TF.describe_t;
BEGIN
-- We only want these two columns
new_cols(1) := dbms_tf.column_metadata_t(name => 'COLUMN_NAME',
TYPE => dbms_tf.type_varchar2);
new_cols(2) := dbms_tf.column_metadata_t(name => 'DATATYPE',
TYPE => dbms_tf.type_varchar2);
-- We don't need any other columns, neither for passing them through
-- nor for reading
FOR I IN 1 .. tab.COLUMN.COUNT LOOP
tab.column(i).pass_through := FALSE;
TAB.COLUMN(i).for_read := FALSE;
END LOOP;
v_sql :=
q'! SELECT DISTINCT
key_name
, first_value(datatype) OVER (PARTITION BY key_name
ORDER BY rnk DESC) datatype
FROM (SELECT key_name
, CASE
WHEN key_val_char IS NOT NULL THEN 'C'
WHEN key_val_date IS NOT NULL THEN 'D'
WHEN key_val_number IS NOT NULL THEN 'N'
ELSE 'C'
END datatype
, CASE
WHEN key_val_char IS NULL
AND key_val_date IS NULL
AND key_val_number IS NULL THEN 0
ELSE 1
END rnk
FROM t)
!'; --'
EXECUTE IMMEDIATE v_sql BULK COLLECT INTO v_colrectab;
-- Save the results into the "compilation strore"
FOR i IN 1..v_colrectab.count LOOP
descr.cstore_chr('c'||i) := v_colrectab(i).column_name;
descr.cstore_chr('d'||i) := v_colrectab(i).datatype;
END LOOP;
descr.new_columns := new_cols;
descr.row_replication:=true;
RETURN descr;
END;
PROCEDURE fetch_rows IS
inp_rs DBMS_TF.row_set_t;
colcnt PLS_INTEGER;
rowcnt PLS_INTEGER;
repfac dbms_tf.tab_naturaln_t;
namecol dbms_tf.tab_varchar2_t;
typcol dbms_tf.tab_varchar2_t;
colname dbms_id;
coltype varchar2(1);
BEGIN
dbms_tf.get_row_set(inp_rs, rowcnt, colcnt);
FOR i IN 1..rowcnt LOOP
repfac(i) := 0;
IF dbms_tf.cstore_exists ('c'||i) THEN
dbms_tf.cstore_get('c'||i, colname);
dbms_tf.cstore_get('d'||i, coltype);
IF NOT dbms_tf.xstore_exists(colname) THEN
namecol(nvl(namecol.last+1,1)) := colname;
typcol(nvl(typcol.last+1,1)) := coltype;
repfac(i) := 1;
dbms_tf.xstore_set(colname,1);
END IF;
END IF;
END LOOP;
dbms_tf.row_replication(replication_factor => repfac);
dbms_tf.put_col(1, namecol);
dbms_tf.put_col(2, typcol);
END;
END get_cols_pkg;
/
Listing 4: Package Body get_cols_pkg
Now we define and test the function itself.
SQL> CREATE OR REPLACE FUNCTION get_cols(tab TABLE) RETURN TABLE 2 PIPELINED row POLYMORPHIC USING get_cols_pkg; 3 / Function GET_COLS compiled SQL> SQL> SELECT * 2 FROM get_cols(t); COLUMN_NAME DATAT ------------------------------ ----- ENAME C HIREDATE D DEPTNO N JOB C SAL N COMM N MGR N 7 rows selected.
Listing 5
It works! But wait a minute! We have hard coded the name of the table into the dynamic SQL query! It is very easy to fix, isn’t it? NO! The function DESCRIBE has indeed the parameter TAB of the record type DBMS_TF.TABLE_T, but there is no such thing as table name there. In fact, this is reasonable since what we can pass in the PTF doesn’t need to be a table, but can be a CTE (common table expression), e.g. a WITH-subquery. As of now I only see the quick and dirty fix of providing an extra string parameter holding whatever to select from: a table name or a subquery text. Listing 6 shows a solution with an extra parameter to_select_from.
CREATE OR REPLACE PACKAGE get_cols_pkg AS
FUNCTION describe(tab IN OUT DBMS_TF.TABLE_T
, to_select_from IN VARCHAR2 )
RETURN DBMS_TF.DESCRIBE_T;
PROCEDURE fetch_rows (to_select_from varchar2 ) ;
END get_cols_pkg;
/
CREATE OR REPLACE PACKAGE BODY get_cols_pkg AS
FUNCTION describe(tab IN OUT DBMS_TF.TABLE_T
, to_select_from IN VARCHAR2 )
RETURN DBMS_TF.DESCRIBE_T
AS
new_cols DBMS_TF.COLUMNS_NEW_T;
col_id PLS_INTEGER := 1;
v_sql VARCHAR2(2000);
type t_colrec is record (column_name dbms_id, datatype varchar2(1));
type t_colrectab is table of t_colrec index by pls_integer;
v_colrectab t_colrectab;
descr DBMS_TF.describe_t;
BEGIN
-- We only want these two columns
new_cols(1) := dbms_tf.column_metadata_t(name => 'COLUMN_NAME',
TYPE => dbms_tf.type_varchar2);
new_cols(2) := dbms_tf.column_metadata_t(name => 'DATATYPE',
TYPE => dbms_tf.type_varchar2);
-- We don't need any other columns, neither for passing them through
-- nor for reading
FOR I IN 1 .. tab.COLUMN.COUNT LOOP
tab.column(i).pass_through := FALSE;
TAB.COLUMN(i).for_read := FALSE;
END LOOP;
v_sql := '
SELECT DISTINCT
key_name
, first_value(datatype) OVER (PARTITION BY key_name
ORDER BY rnk DESC) datatype
FROM (SELECT key_name
, CASE
WHEN key_val_char IS NOT NULL THEN ''C''
WHEN key_val_date IS NOT NULL THEN ''D''
WHEN key_val_number IS NOT NULL THEN ''N''
ELSE ''C''
END datatype
, CASE
WHEN key_val_char IS NULL
AND key_val_date IS NULL
AND key_val_number IS NULL THEN 0
ELSE 1
END rnk
FROM ('||to_select_from||') t) '; --'
EXECUTE IMMEDIATE v_sql BULK COLLECT INTO v_colrectab;
-- Save the results into the "compilation strore"
FOR i IN 1..v_colrectab.count LOOP
descr.cstore_chr('c'||i) := v_colrectab(i).column_name;
descr.cstore_chr('d'||i) := v_colrectab(i).datatype;
END LOOP;
descr.new_columns := new_cols;
descr.row_replication:=true;
RETURN descr;
END;
PROCEDURE fetch_rows ( to_select_from VARCHAR2 ) IS
inp_rs DBMS_TF.row_set_t;
colcnt PLS_INTEGER;
rowcnt PLS_INTEGER;
repfac dbms_tf.tab_naturaln_t;
namecol dbms_tf.tab_varchar2_t;
typcol dbms_tf.tab_varchar2_t;
colname dbms_id;
coltype varchar2(1);
BEGIN
dbms_tf.get_row_set(inp_rs, rowcnt, colcnt);
FOR i IN 1..rowcnt LOOP
repfac(i) := 0;
IF dbms_tf.cstore_exists ('c'||i) THEN
dbms_tf.cstore_get('c'||i, colname);
dbms_tf.cstore_get('d'||i, coltype);
IF NOT dbms_tf.xstore_exists(colname) THEN
namecol(nvl(namecol.last+1,1)) := colname;
typcol(nvl(typcol.last+1,1)) := coltype;
repfac(i) := 1;
dbms_tf.xstore_set(colname,1);
END IF;
END IF;
END LOOP;
dbms_tf.row_replication(replication_factor => repfac);
dbms_tf.put_col(1, namecol);
dbms_tf.put_col(2, typcol);
END;
END get_cols_pkg;
/
SQL> CREATE OR REPLACE FUNCTION get_cols(tab TABLE
2 , to_select_from varchar2 )
3 RETURN TABLE
4 PIPELINED row POLYMORPHIC USING get_cols_pkg;
5 /
Function GET_COLS compiled
SQL>
SQL> WITH tsub as (SELECT * FROM T WHERE empno != 7839)
2 SELECT *
3 FROM get_cols(tsub, 'SELECT * FROM T WHERE empno != 7839');
COLUMN_NAME DATAT
------------------------------ -----
ENAME C
HIREDATE D
DEPTNO N
JOB C
SAL N
COMM N
MGR N
7 rows selected.
Listing 6
Well, this works, even with a subquery. But from my point of view it is far from an elegant solution… And caution, simply concatenating a parameter into dynamic query is a clear no-go in terms of SQL injection!
PTF for transposing rows to columns
Now it is a diligent but routine piece of work to construct an implementation package for the transposing function based on this approach.
What should the function, let’s name it KEYVAL2TAB, do? Well, it should act as a kind of grouping function: we need to process all rows for particular EMPNO returning only one row with all column values.
It is where table semantic PTF and the ability to partition the input data (like with analytic functions) come into play. The invocation of the function should look like this:
SELECT * FROM keyval2tab(t PARTITION BY empno,'T');
Listing 7
I think the package code (Listing 8) needs some explanations too.
Function DESCRIBE:
- Lines 24-35: All other columns except KEY_NAME and the three “value”-columns are “identifying”. We just want to take them over as is and are therefore adding them to NEW_COLS. Actually I supposed, this should work by specifying the property pass_through=true for them, but I didn’t manage this to work. Maybe it was a bug in my code or it is not supposed to work in this manner with row replication – I don’t know at this moment. It needs further investigation. I’ll write on it later.
For now we just define such “identifying” columns as new, count them (line 29) and save the count in compilation store for later use within FETCH_ROWS - Lines 37-70: It’s time to define “transposed” columns using the approach we just tried with the package GET_COLS_PKG. The difference is that we don’t need to store the column names and data types in compilation store but can directly define then as new columns (filling the collection NEW_COLS)
Procedure FETCH_ROWS:
- Line 93: Get input row set
- Lines 95-99: We want to collapse all rows from one partition to just one: set replication factor to 0 for all rows except the first
- Line 100: Get the saved number of identifying columns from compilation store
- Lines 102-108: Reassign the values of this columns from input to the output result set. I think it’s time to explain how the result sets (input and output) are constructed. Please refer to Figure 2 for better understanding. The portion of the fetched data flows into the table type ROW_SET_T which is a table of records of the type COLUMN_DATA_T. Which in turn has a DESCRIPTION (record type COLUMN_METADATA_T) and fifteen so called variant fields for all supported types. These variant fields are actually collections (associative arrays or index-by tables in terms of PL/SQL). Only one variant field of the proper data type is active for one column.
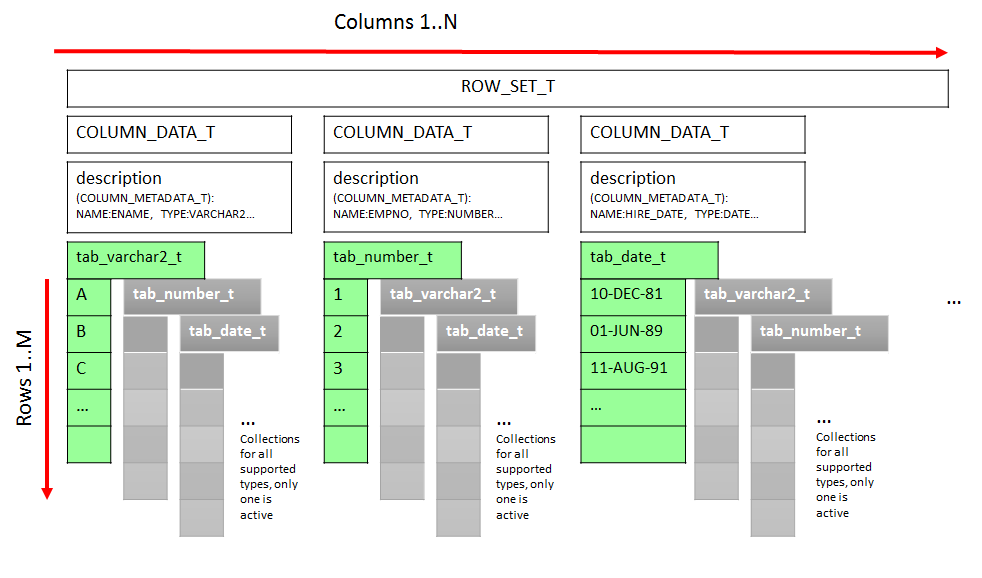
Figure 2ENV_T is record type containing the information about current execution state. We use it to get a list of put columns
- Lines 110-122: Looping through rows and columns we gather the actual values for every output column. Once again, we are filling only one row in the output row set: out_rs(p).tab_varchar2(1) means we reference the first row and P-th column which is of type VARCHAR2
CREATE OR REPLACE PACKAGE kv2tab_pkg AS
FUNCTION describe(tab IN OUT DBMS_TF.TABLE_T, to_select_from IN VARCHAR2 )
RETURN DBMS_TF.DESCRIBE_T;
PROCEDURE fetch_rows (to_select_from varchar2 ) ;
END kv2tab_pkg;
/
CREATE OR REPLACE PACKAGE BODY kv2tab_pkg AS
FUNCTION describe(tab IN OUT DBMS_TF.TABLE_T, to_select_from IN VARCHAR2 )
RETURN DBMS_TF.DESCRIBE_T
AS
new_cols DBMS_TF.COLUMNS_NEW_T;
col_id PLS_INTEGER := 1;
idcol_cnt PLS_INTEGER := 0;
v_sql VARCHAR2(2000);
type t_colrec is record (column_name dbms_id, datatype varchar2(1));
type t_colrectab is table of t_colrec index by pls_integer;
v_colrectab t_colrectab;
descr DBMS_TF.describe_t;
BEGIN
--
FOR I IN 1 .. tab.COLUMN.COUNT LOOP
IF tab.COLUMN(i).description.name NOT IN ('"KEY_NAME"','"KEY_VAL_NUMBER"','"KEY_VAL_CHAR"','"KEY_VAL_DATE"') THEN
new_cols(col_id) := dbms_tf.column_metadata_t(name => tab.COLUMN(i).description.name
, TYPE => tab.COLUMN(i).description.type);
col_id := col_id +1;
idcol_cnt := idcol_cnt +1;
END IF;
tab.column(i).pass_through := FALSE;
TAB.COLUMN(i).for_read := TRUE;
END LOOP;
descr.cstore_num('idcols') := idcol_cnt;
v_sql := '
SELECT DISTINCT
key_name
, first_value(datatype) OVER (PARTITION BY key_name
ORDER BY rnk DESC) datatype
FROM (SELECT key_name
, CASE
WHEN key_val_char IS NOT NULL THEN ''C''
WHEN key_val_date IS NOT NULL THEN ''D''
WHEN key_val_number IS NOT NULL THEN ''N''
ELSE ''C''
END datatype
, CASE
WHEN key_val_char IS NULL
AND key_val_date IS NULL
AND key_val_number IS NULL THEN 0
ELSE 1
END rnk
FROM ('||to_select_from||') t) ';
EXECUTE IMMEDIATE v_sql BULK COLLECT INTO v_colrectab;
FOR i IN 1..v_colrectab.count LOOP
case v_colrectab(i).datatype
when 'C' then NEW_COLS(col_id) := dbms_tf.column_metadata_t(name => v_colrectab(i).column_name
, TYPE => dbms_tf.type_varchar2);
when 'D' then NEW_COLS(col_id) := dbms_tf.column_metadata_t(name => v_colrectab(i).column_name
, TYPE => dbms_tf.type_date);
when 'N' then NEW_COLS(col_id) := dbms_tf.column_metadata_t(name => v_colrectab(i).column_name
, TYPE => dbms_tf.type_number);
end case;
col_id := col_id +1;
END LOOP;
descr.new_columns := new_cols;
descr.row_replication:=true;
RETURN descr;
END;
PROCEDURE fetch_rows ( to_select_from VARCHAR2 ) IS
inp_rs DBMS_TF.row_set_t;
out_rs DBMS_TF.row_set_t;
env dbms_tf.env_t := dbms_tf.get_env();
colcnt PLS_INTEGER;
rowcnt PLS_INTEGER;
repfac dbms_tf.tab_naturaln_t;
namecol dbms_tf.tab_varchar2_t;
typcol dbms_tf.tab_varchar2_t;
colname dbms_id;
coltype varchar2(1);
idcol_cnt pls_integer;
BEGIN
DBMS_TF.get_row_set(inp_rs, rowcnt, colcnt);
FOR i IN 1 .. rowcnt LOOP
repfac(i) := 0;
END LOOP;
repfac(1) := 1;
dbms_tf.cstore_get('idcols', idcol_cnt);
FOR i IN 1..idcol_cnt LOOP
IF env.put_columns(i).type = dbms_tf.type_number THEN
out_rs(i).tab_number(1):= inp_rs(i).tab_number(1);
ELSIF env.put_columns(i).type = dbms_tf.type_varchar2 THEN
out_rs(i).tab_varchar2(1):= inp_rs(i).tab_varchar2(1);
END IF;
END LOOP;
FOR r IN 1 .. rowcnt LOOP
FOR p IN 1 .. env.put_columns.count LOOP
IF inp_rs(idcol_cnt+1).tab_varchar2(r)=replace(env.put_columns(p).name,'"') THEN
IF env.put_columns(p).type = dbms_tf.type_varchar2 then
out_rs(p).tab_varchar2(1):= inp_rs(idcol_cnt+2).tab_varchar2(r);
ELSIF env.put_columns(p).type = dbms_tf.type_number then
out_rs(p).tab_number(1):= inp_rs(idcol_cnt+3).tab_number(r);
ELSIF env.put_columns(p).type = dbms_tf.type_date then
out_rs(p).tab_date(1):= inp_rs(idcol_cnt+4).tab_date(r);
END IF;
END IF;
END LOOP;
END LOOP;
dbms_tf.put_row_set (out_rs, repfac);
END;
END kv2tab_pkg;
/
Listing 8
Now we can create and test our function. And it works. If we were to add some more yet unknown keys with values to the table T, would you expect the PTF will return these as new columns? Well, actually it should, but it would not. This is the price for doing nasty things like dynamic SQL in the DESCRIBE function. We have made the shape of the result set to be dependent on the data. But the database has no clue about it. It has no reason to invalidate the cursor and to hard parse the statement again and thus we cannot see the new column. We have to flush the shared pool or slightly change the query to make hard parse happen again.
SQL> CREATE OR REPLACE FUNCTION keyval2tab(tab TABLE, to_select_from VARCHAR2 ) RETURN TABLE
2 PIPELINED table POLYMORPHIC USING kv2tab_pkg;
3 /
Function KEYVAL2TAB compiled
SQL>
SQL>
SQL> SELECT * FROM keyval2tab(t PARTITION BY empno,'T') FETCH FIRST 10 ROWS ONLY;
EMPNO ENAME HIREDATE DEPTNO JOB SAL COMM MGR
---------- -------------------- --------- ---------- ---------- ---------- ---------- ----------
7369 SMITH 17-DEC-80 20 CLERK 800 7902
7499 ALLEN 20-FEB-81 30 SALESMAN 1600 300 7698
7521 WARD 22-FEB-81 30 SALESMAN 1250 500 7698
7566 JONES 02-APR-81 20 MANAGER 2975 7839
7654 MARTIN 28-SEP-81 30 SALESMAN 1250 1400 7698
7698 BLAKE 01-MAY-81 30 MANAGER 2850 7839
7782 CLARK 09-JUN-81 10 MANAGER 2450 7839
7788 SCOTT 19-APR-87 20 ANALYST 3000 7566
7839 KING 17-NOV-81 10 PRESIDENT 5000
7844 TURNER 08-SEP-81 30 SALESMAN 1500 0 7698
10 rows selected.
SQL> INSERT INTO t (empno, key_name, key_val_char) VALUES(7839, 'NEW_COLUMN', 'NEW_VALUE');
1 row inserted.
SQL>
SQL> SELECT * FROM keyval2tab(t PARTITION BY empno,'T') FETCH FIRST 10 ROWS ONLY;
EMPNO ENAME HIREDATE DEPTNO JOB SAL COMM MGR
---------- -------------------- --------- ---------- ---------- ---------- ---------- ----------
7369 SMITH 17-DEC-80 20 CLERK 800 7902
7499 ALLEN 20-FEB-81 30 SALESMAN 1600 300 7698
7521 WARD 22-FEB-81 30 SALESMAN 1250 500 7698
7566 JONES 02-APR-81 20 MANAGER 2975 7839
7654 MARTIN 28-SEP-81 30 SALESMAN 1250 1400 7698
7698 BLAKE 01-MAY-81 30 MANAGER 2850 7839
7782 CLARK 09-JUN-81 10 MANAGER 2450 7839
7788 SCOTT 19-APR-87 20 ANALYST 3000 7566
7839 KING 17-NOV-81 10 PRESIDENT 5000
7844 TURNER 08-SEP-81 30 SALESMAN 1500 0 7698
10 rows selected.
SQL>
SQL> SELECT * FROM keyval2tab(t PARTITION BY empno,'T') ORDER BY EMPNO FETCH FIRST 10 ROWS ONLY;
EMPNO ENAME HIREDATE DEPTNO JOB SAL COMM NEW_COLUMN MGR
---------- -------------------- --------- ---------- ---------- ---------- ---------- ---------- ----------
7369 SMITH 17-DEC-80 20 CLERK 800
7499 ALLEN 20-FEB-81 30 SALESMAN 1600 300
7521 WARD 22-FEB-81 30 SALESMAN 1250 500
7566 JONES 02-APR-81 20 MANAGER 2975
7654 MARTIN 28-SEP-81 30 SALESMAN 1250 1400
7698 BLAKE 01-MAY-81 30 MANAGER 2850
7782 CLARK 09-JUN-81 10 MANAGER 2450
7788 SCOTT 19-APR-87 20 ANALYST 3000
7839 KING 17-NOV-81 10 PRESIDENT 5000 NEW_VALUE
7844 TURNER 08-SEP-81 30 SALESMAN 1500 0
10 rows selected.
Listing 8
Conclusion
Well, we created a function which was indeed able to transpose rows to columns dynamically, e.g. we didn’t have to know what columns were actually there. But – let me emphasize that – I don’t believe it is a feasable solution. Maybe for some kind of explorative analysis tasks, if you are looking into unknown data set for the first time. We had to work around one problem after another and ended up with quite strange invocation and our PTF is scanning all the data twice. The bottom line: it seems to me that the cases where we need the result set based on the input data, rather then structure or parameters, are in general not a good area of application for polymorphic table functions.
Do you have another ideas? Your comments are welcome!
Hello Andrej,
I just found your new post about the PTF functions, and I just want to thank you a lot for your tremendous work :):)
I think that the Oracle documentation of the PTF functions overall functionality, both in the PL/SQL User Guide and in the Packages reference for the DBMS_TF package is lacking a lot of information.
The technical details of the many record and collection types can be somehow understood,
but what is missing is some more detailed explanation of how exactly the processing occurs,
or, more specifically, at what point is each implementation procedure invoked and when are
the various data structures populated.
For example, the presentation of GET_ENV and ENV_T do not explain at all where in the processing flow
do they intervene and how.
I have the feeling that the only way of learning currently available is to look at the examples and try to understand the functionality by reverse-engineering those examples, instead of gaining first a full understanding of the various processing steps involved.
Your examples and explanations are extremely welcome for a deeper understanding and
I will be extremely grateful to you if you will find the time to elaborate the step-by-step posts that
you mentioned at the start of this post.
It would be great if you could make these step-by-step posts into a logical series, introducing all the features gradually, in their logical order, like a set of lessons, building each post on the understanding
and knowledge gained from the previous posts.
Thanks a lot once again for your great work 🙂
Best Regards,
Iudith Mentzel
Hello,
I have a question about the strange behavior of the package after adding a new parameter (new row to the T table). Before adding the parameter, the query result is as follows.
SQL> SELECT * FROM keyval2tab(t PARTITION BY empno,'T');EMPNO DEPTNO SAL HIREDATE COMM JOB MGR ENAME
________ _________ _______ ___________ _______ ____________ _______ _________
7369 20 800 80/12/17 CLERK 7902 SMITH
7499 30 1600 81/02/20 300 SALESMAN 7698 ALLEN
7521 30 1250 81/02/22 500 SALESMAN 7698 WARD
7566 20 2975 81/04/02 MANAGER 7839 JONES
7654 30 1250 81/09/28 1400 SALESMAN 7698 MARTIN
7698 30 2850 81/05/01 MANAGER 7839 BLAKE
7782 10 2450 81/06/09 MANAGER 7839 CLARK
7788 20 3000 87/04/19 ANALYST 7566 SCOTT
7839 10 5000 81/11/17 PRESIDENT KING
7844 30 1500 81/09/08 0 SALESMAN 7698 TURNER
7876 20 1100 87/05/23 CLERK 7788 ADAMS
7900 30 950 81/12/03 CLERK 7698 JAMES
7902 20 3000 81/12/03 ANALYST 7566 FORD
7934 10 1300 82/01/23 CLERK 7782 MILLER
14 rows selected.
SQL> INSERT INTO t (empno, key_name, key_val_char) VALUES(7839, 'NEW_COLUMN', 'NEW_VALUE');
1 row inserted.
SQL> commit;
Commit complete.
After adding the parameter and flush shared_pool, the query result is incorrect.
SQL> SELECT * FROM keyval2tab(t PARTITION BY empno,'T');
EMPNO DEPTNO SAL HIREDATE NEW_COLUMN COMM JOB MGR ENAME
________ _________ _______ ___________ _____________ _______ ____________ ______ ________
7369 20 800 80/12/17
7499 30 1600 81/02/20
7521 30 1250 81/02/22
7566 20 2975 81/04/02
7654 30 1250 81/09/28
7698 30 2850 81/05/01
7782 10 2450 81/06/09
7788 20 3000 87/04/19
7839 10 5000 81/11/17 NEW_VALUE PRESIDENT KING
7844 30 1500 81/09/08
7876 20 1100 87/05/23
7900 30 950 81/12/03
7902 20 3000 81/12/03
7934 10 1300 82/01/23
14 rows selected.
Could you explain why this happened?
How can this be fixed?
Best regards,
Rafal
Hello Rafal,
thank you for asking. I could reproduce the issue and I know the reason why it is happening. In fact, I missed the bug in my post: the last query returns all NULL’s for the column MGR. I have overlooked this!
In short, this has to do with the way I’m filling the output result set and with the handling of NO_DATA_FOUND. However, the more detailed explanation may be more complex and longer, so I decided to write a follow-up post on this.
I’ll try my best to finish it this week.
Best Regards
Andrej
Hello Rafal,
I have finished the post with the explanation of the problem: Beware of NO_DATA_FOUND in your PTF!
I hope this helps but of course if you have more questions – you are welcome!
Best Regards
Andrej