

Letzten Monat konnte ich an der DOAG-Jahreskonferenz in Nürnberg teilnehmen. Wie immer ein tolles Event, großartige Community und exzellente Vorträge. Und es scheint so zu sein, als hätte ich mein Lieblings-Feature der neuen Datenbank 18c gefunden. Keith Laker (@ASQLBarista), Oracle’s Produkt Manager für Analytisches SQL, sparch über „Building Agile Self-Describing SQL Functions For Big Data“. Der Vortragstitel war sehr vielversprechend und natürlich war ich nicht enttäuscht. Danke für sehr interessante Präsentation!
Dieser Beitrag ist wohl etwas ungewöhnlich, weil ich noch kein echtes Know-How teilen kann, sondern erstmal meine Begeisterung über die Mächtigkeit und Flexibilität von dem neuen Feature. Worum geht es bei dem Begriff „Polymorphic Table Functions“?
Wahrscheinlich ist Ihnen bereits das Konzept von Tabellenfunktionen bekannt. Diese können „pipelined“ sein oder nicht, das ist nicht relevant. Wichtig ist, man kann aus so einer Funktion in SQL „selektieren“:
select * from table(dbms_xplan.display);
Die zweite wichtige Eigenschaft, ist dass die Tabellenfunktionen immer einen definierten Tabellen-Datentyp zurückgeben. Zum Beispiel, liefert dbms_xplan.display den Typ dbms_xplan_type_table zurück, der als TABLE OF VARCHAR2(4000) definiert ist. Es kann nicht passieren, dass die Logik in der Funktion dbms_xplan.display diesen Datentyp ändert. Der Tabellen-Datentyp ist fix. Und das ist ein Hindernis, um flexible und generische Erweiterungsfunktionen implementieren zu können.
Aber auch die Implementierung spezifischer Funktionen kann problematisch sein. Vielleicht haben Sie sich gefargt, wie gehe ich mit parallelen Ausführung um? Wenn Sie sich nach den Möglichkeiten umgeschaut haben, wie man Strings aggregieren (konkatenieren) kann, bevor die Funktion LISTAGG in 11g eingeführt wurde, haben sie bestimmt schon mal die Tom Kyte’s Implementierung von der Funktion STRAGG gesehen. Nicht wirklich einfach, über einen Objekttyp mit vier Methoden, unter anderem einer Methode, um die Teilergebnisse nach der parallelen Ausführung zu „mergen“.
Polymorphe Tabellenfunktionen (PTF) adressieren diese Probleme. Polymorphe Tabellenfunktionen sind Teil von ANSI SQL 2016 Standard und sind eine Evolution der Tabellenfunktionen. Sie können in der FROM-Klausel aufgerufen werden, akzeptieren Daten aus beliebiger Tabellen (oder WITH-Unterabfragen). Der Rückgabe-Datentyp muss nicht bei Entwicklung festgelegt werden. Die Funktion kann die Daten verarbeiten, dabei Datensätze hinzufügen oder weggruppieren, Spalten hinzufügen oder herausnehmen, und die verarbeiteten Daten weiter aus der Funktion an die SQL-Abfrage zurückgeben. Der Datentyp der zurückgegebener Tabelle muss nicht vorher definiert werden.
Ich verzichte auf mein eigenes Beispiel, weil es eine Spekulation wäre, ohne es selber in einer Datenbank ausprobiert zu haben. Hier ist das Beispiel aus dem Vortrag von Keith Laker: Kredit-Score und Risiko-Level eines Kunden zurückgeben:
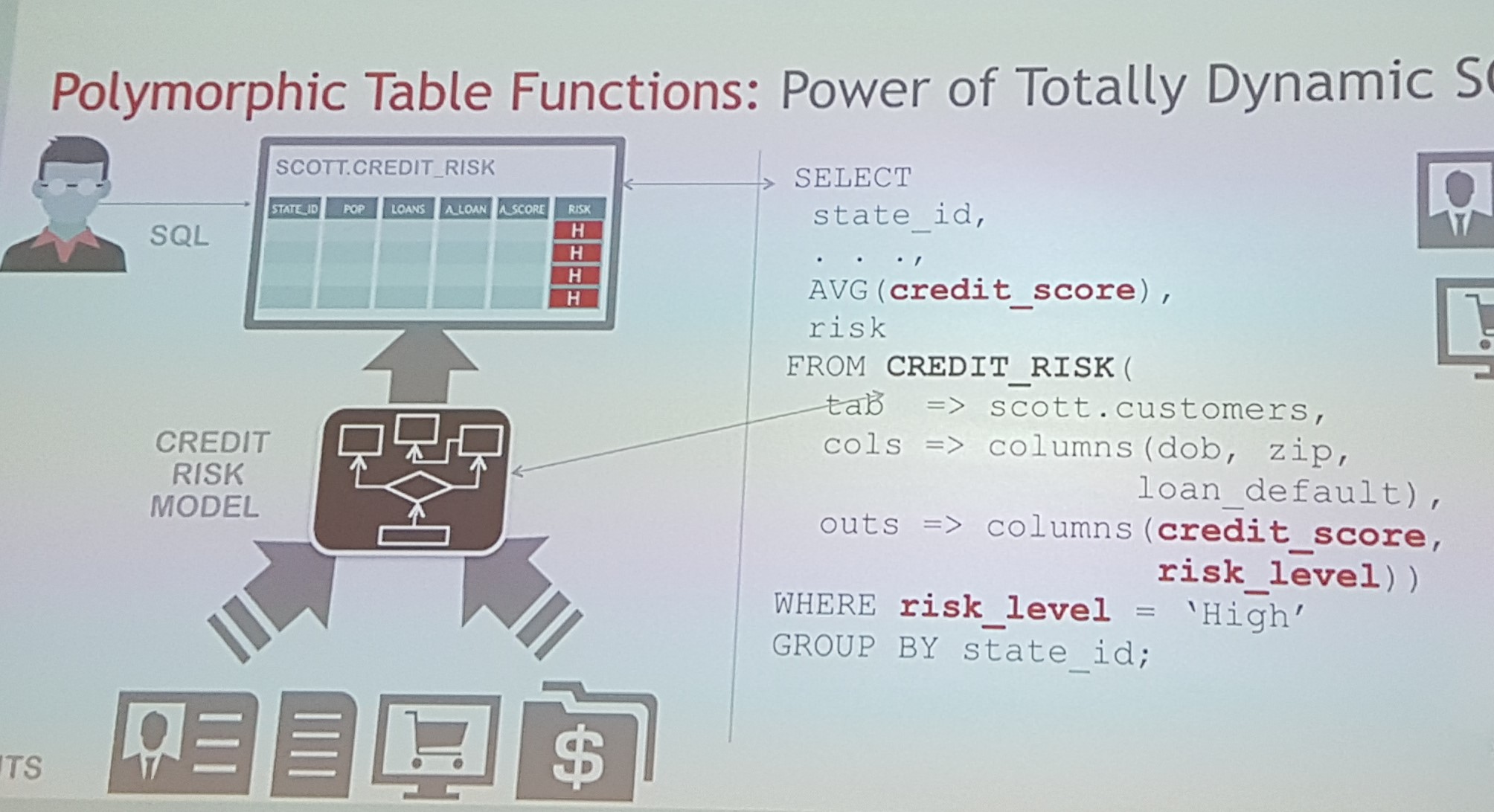
Wir übergeben die Tabelle scott.customers in die Funktion CREDIT_RISK, definieren die Spalten, die man für Berechnungen braucht und die Spalten, die zurückgegeben werden müssen. Eigentlich bin ich der Meinung, dass wir hier noch die Spalte STATE_ID im Parameter OUTS erwähnen sollten, damit wir danach gruppieren können. Kann aber sein, dass ich etwas missverstanden habe. Das war’s. Wir können aus der Funktion einfach selektieren: die neu berechneten Spalten sind an jedem Datensatz dran und können gruppiert werden.
Mann kann „Leaf“ und „Non-Leaf“ PTFs unterscheiden und die letzten können row semantic (RS PTF) oder table semantic (TS PTF) sein. Der Unterschied ist, dass man bei row semantic nur den aktuellen Datensatz braucht, um alle Outputs zu produzieren. Bei table semantic muss man auf die vorher verarbeiteten Datensätze schauen, um neue Spalten oder Datensätze zu generieren – hier geht es eher um eine Art Aggregat-/analytische Funktionen. Mit TS PTF kann man optional den Input partitionieren und ordnen (wie bei analytischen Funktionen):
SELECT * FROM CUSTOM_GRPBY(scott.emp PARTITION BY job ORDER BY empno);
Wie sieht es mit parallelen Ausführung aus? Die Aussage ist, der Entwickler kann einfach von einer seriellen Ausführung ausgehen. Alles andere wird durch die Datenbank geregelt. Mit einer Anmerkung: bei Tabellensemantik muss man die Partitionierung mit angeben, wie im Beispiel oben. Alle Datensätze einer Partition landen auf demselben Parallel Slave. Gibt man die Partitionierung nicht an, wird die Funktion zu einem Serialisierungspunkt.
Es gibt auch ein paar gute Neuigkeiten für Performance: Bulk-Übertragung der Daten in die und aus der Funktion, wobei nur die benötigten Spalten übertragen werden. Soweit möglich, werden die Prädikate, Partitionierung in die darunterliegende Tabelle weitergereicht.
Alle Datentypen und Hilfsroutinen zum Implementieren der PTFs sind im Package DBMS_TF zu finden. Übrigens, das Package ist bereits in der Version 12.2.0.1 da, wenn auch (noch) nicht dokumentiert. Sie können sogar versuchen, ihre erste PTF anzulegen, es geht aber nicht ganz. Schließlich ist es ein 18c Feature!
create or replace package ptf_test as
procedure describe (new_cols out dbms_tf.columns_new_t, tab in out dbms_tf.table_t, cols dbms_tf.columns_t) ;
function my_ptf (tab table, type_name varchar2, flip varchar2 default 'True')
return table pipelined row polymorphic using ptf_test;
end;
/
show errors
LINE/COL ERROR
-------- --------------------------------------------------------
3/124 PLS-00998: implementation restriction (may be temporary)
Welche interessante Anwendungsfälle kann ich mir vorstellen? Im Moment arbeite ich an der Integration der Daten in einem Data Warehouse System, die ursprünglich aus einem XBRL Format stammen. In der Quelldatenbank werden diese XBRL-Daten in einer sog. „Key-Value“ Tabelle persistiert. Nun sind die Anforderungen, wie man mit DAtensätzen aus der riesigen Key-Value-Tabelle umgeht, unterschiedlich, meistens abhängig von den Key-Werten und sind SQL-technisch nicht „kompatibel“. Mal muss man diese aggregieren, mal pivotieren auch mit Erkennung von sog. „Tupeln“, mal noch was anderes. Dies macht mehrfaches Scannen der großen Tabelle nötig. Was wäre, wenn wir die Möglichkeit hätten, die Tabelle nur einmal zu scannen und dann innerhalb einer PTF die Datensätze bedingt aggregieren, pivotieren, was auch immer? Man könnte einen ETL-Prozess entwickeln, der aus einer großen Tabelle liest, reicht die Daten in die PTF weiter, die unterschiedliche Datenströme vorbereitet, und leitet die anschließend über INSERT ALL SQL Statement in mehrere Zieltabellen weiter. Alles in einem Schritt. Wenn das auch schnell läuft, warum nicht?
Apropos Pivot, wird es wohl auch möglich sein, eine Funktion für dynamisches PIVOT zu entwickeln, wobei man nicht zur Entwicklungszeit festlegen muss, welche Werte zu Spalten werden, ähnlich wie die von Anton Scheffer, aber ohne, dass man den Abfragetext übergeben muss? Vielleicht habe ich noch was übersehen, aber erstmal es klingt gut für mich.
Wenn alles so funktioniert wie versprochen und auch schnell und skalierbar ist, wird es ein sehr interessantes Feature! Abwarten! Bleiben Sie dran, ich werde definitiv im nächsten Jahr über Polymorphische Funktionen schreiben und ich kann es kaum erwarten, an den Beispielen und Folien zu diesem Thema für unseren Kurs New Features Training zu arbeiten.