
Preparing my session on Online Statistics Gathering for ETL for the DOAG conference, I noticed some points that I didn’t covered in the previous two blog posts. The first point is showing the problem that may arise if indexes are involved. The second one is about partition exchange load and it completes the topic of partitioned tables started in part 2. No blog posting on Oracle products is nowadays complete without mentioning the cloud. The third point is about Autonomous Data Warehouse Cloud Service and Online Statistics Gathering improvements.
Don’t forget your indexes!
Had you also had the situation that after a failure the ETL processes suddenly became significantly slower? The following may have been the reason.
With online statistics gathering only table and base column statistics are gathered. If you have indexes you should care of them on your own. What does it mean for ETL? Well, the first best practice says, don’t overindex your DWH. If you considered dropping an index and still opted for it, then it is highly likely that you are already following another best practice for bulk loads into a table/partition: drop or set unusable your indexes/index partitions before loading and recreate/rebuild them afterwards. Index statistics will be gathered automatically (yes, for indexes the online statistics gathering was introduced already in 9i). Otherwise make sure, you will never gather index stats on empty table before loading. In this case the older index statistics are better then newer (but empty).
Consider following example.
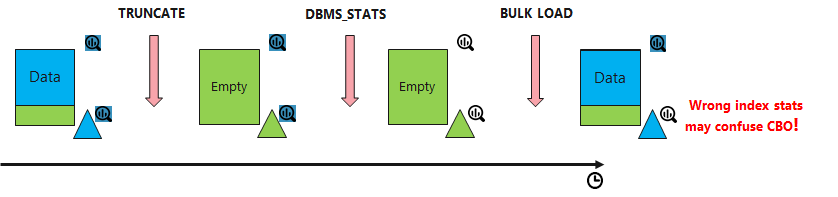
Figure 2: Index statistics are lost because of DBMS_STATS run in between
You have a table with index, containing data, with both table and index stats in place. You then truncate the table, but for some reason don’t load new data immediately after that (failure in ETL process or maybe you are yet testing and haven’t yet automated everything) . Truncate doesn’t throw away table and index statistics. But what if statistics on the table and index will be gathered by the regular DBMS_STATS job during the maintenance window? After that NUM_ROWS for the table and also NUM_DISTINCT_KEYS for the index will be 0. After loading we will get newer stats for the table via online statistics gathering, but unfortunately not for the index. And guess what the optimizer will do with the index? It will obviously base its cardinality estimation on it and use the index!
SQL> create table t_osg ( n number , n2 number default 1, pad varchar2(300));
Table T_OSG created.
SQL> insert /*+ append */ into t_osg
2 select level n,
3 case when mod(level, 3) = 0 then null else mod(level, 3) end,
4 rpad ('***************',300,'/')
5 from dual connect by level <= 100000;
100,000 rows inserted.
SQL> commit;
Commit complete.
SQL> -- Second table as a copy of the first
SQL> create table t_osg2 as select * from t_osg;
Table T_OSG2 created.
SQL> create unique index t1_i on t_osg (n);
Index T1_I created.
SQL> select index_name, distinct_keys, last_analyzed
2 from user_indexes i where index_name = 'T1_I';
INDEX_NAME DISTINCT_KEYS LAST_ANALYZED
------------------------------ ------------- -------------------
T1_I 100000 28.10:2018 06:46:14
SQL>
SQL> select table_name, num_rows, last_analyzed
2 from user_tables
3 where table_name like 'T_OSG%';
TABLE_NAME NUM_ROWS LAST_ANALYZED
------------------------------ ---------- -------------------
T_OSG 100000 28.10:2018 06:46:11
T_OSG2 100000 28.10:2018 06:46:13
SQL>
SQL> explain plan for
2 select t1.n, t2.n2, t1.pad ppp1
3 from t_osg t1 join t_osg2 t2 on t1.n = t2.n;
Explained.
SQL>
SQL> select * from table(dbms_xplan.display);
Plan hash value: 3216524395
-------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 100K| 29M| | 4101 (1)| 00:00:01 |
|* 1 | HASH JOIN | | 100K| 29M| 1960K| 4101 (1)| 00:00:01 |
| 2 | TABLE ACCESS FULL| T_OSG2 | 100K| 781K| | 1251 (1)| 00:00:01 |
| 3 | TABLE ACCESS FULL| T_OSG | 100K| 29M| | 1251 (1)| 00:00:01 |
-------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("T1"."N"="T2"."N")
15 rows selected.
Listing 1: Setup for the test case. The normal execution plan contains a hash join.
Create two tables T_OSG and T_OSG2 with an index on T_OSG, verify that both tables and index have statistics. Verify the execution plan for the join of two tables: it is a hash join, doesn’t use the index and the estimations are accurate. Now let’s simulate the problem:
SQL> --- Truncate the first table T_OSG
SQL> truncate table t_osg;
Table T_OSG truncated.
SQL>
SQL> -- The standard oracle job runs in the maintenace window
SQL> begin
2 dbms_stats.gather_table_stats(ownname=> user, tabname=>'T_OSG' );
3 end;
4 /
PL/SQL procedure successfully completed.
SQL>
SQL> -- Stats are gone
SQL> select index_name, distinct_keys, last_analyzed
2 from user_indexes i where index_name = 'T1_I';
INDEX_NAME DISTINCT_KEYS LAST_ANALYZED
------------------------------ ------------- -------------------
T1_I 0 28.10:2018 06:46:16
SQL>
SQL> select table_name, num_rows, last_analyzed
2 from user_tables
3 where table_name like 'T_OSG%';
TABLE_NAME NUM_ROWS LAST_ANALYZED
------------------------------ ---------- -------------------
T_OSG2 100000 28.10:2018 06:46:13
T_OSG 0 28.10:2018 06:46:15
SQL>
SQL> -- Load data once more
SQL>
SQL> insert /*+ append */ into t_osg
2 select level n,
3 case when mod(level, 3) = 0 then null else mod(level, 3) end,
4 rpad ('***************',300,'/')
5 from dual connect by level <= 100000;
100,000 rows inserted.
SQL>
SQL> commit;
Commit complete.
SQL>
SQL> -- table stats are there, but not the index stats
SQL> select index_name, distinct_keys, last_analyzed
2 from user_indexes i where index_name = 'T1_I';
INDEX_NAME DISTINCT_KEYS LAST_ANALYZED
------------------------------ ------------- -------------------
T1_I 0 28.10:2018 06:46:16
SQL>
SQL> select table_name, num_rows, last_analyzed
2 from user_tables
3 where table_name like 'T_OSG%';
TABLE_NAME NUM_ROWS LAST_ANALYZED
------------------------------ ---------- -------------------
T_OSG2 100000 28.10:2018 06:46:13
T_OSG 100000 28.10:2018 06:46:17
SQL>
SQL>
SQL> explain plan for
2 select t1.n, t2.n2, t1.pad ppp2
3 from t_osg t1 join t_osg2 t2 on t1.n = t2.n;
Explained.
SQL>
SQL> select * from table(dbms_xplan.display);
Plan hash value: 3291465260
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 100K| 29M| 1254 (1)| 00:00:01 |
| 1 | NESTED LOOPS | | 100K| 29M| 1254 (1)| 00:00:01 |
| 2 | NESTED LOOPS | | 100K| 29M| 1254 (1)| 00:00:01 |
| 3 | TABLE ACCESS FULL | T_OSG2 | 100K| 781K| 1251 (1)| 00:00:01 |
|* 4 | INDEX UNIQUE SCAN | T1_I | 1 | | 0 (0)| 00:00:01 |
| 5 | TABLE ACCESS BY INDEX ROWID| T_OSG | 1 | 306 | 0 (0)| 00:00:01 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("T1"."N"="T2"."N")
17 rows selected.
Listing 2: switched to nested loops because of index statistics
After truncating the table and gathering statistics on it, the index statistics are indicating the index is empty. As expected, after repeated direct-path load into the table the index statistics are not refreshed. How does the execution plan for the join look like now? The empty index seems to be very appealing for the optimizer as access path for the table T_OSG leading to Nested Loops as join method.
Bulk Load via Partition Exchange
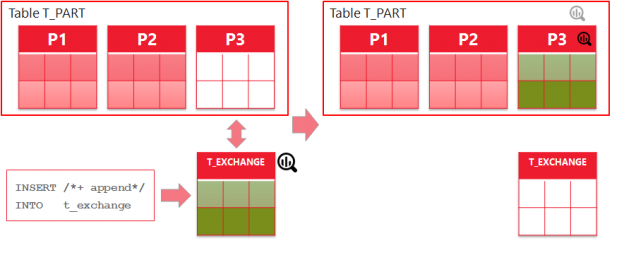
In the second part of the OSG series we’ve considered different scenarios of bulk loading data into partitioning tables, except for the case of partition exchange loading, which is in fact a very efficient way of loading mass data. With partition exchange load (PEL) you are loading data into a separate table created especially for exchange. After load this table will be „exchanged“ with the desired partition without copying of data, just data dictionary operation. You know, in 12c, if you are loading data into an empty exchange table via direct path load, its statistics will be gathered online. But how about partitioned table after exchange operation?
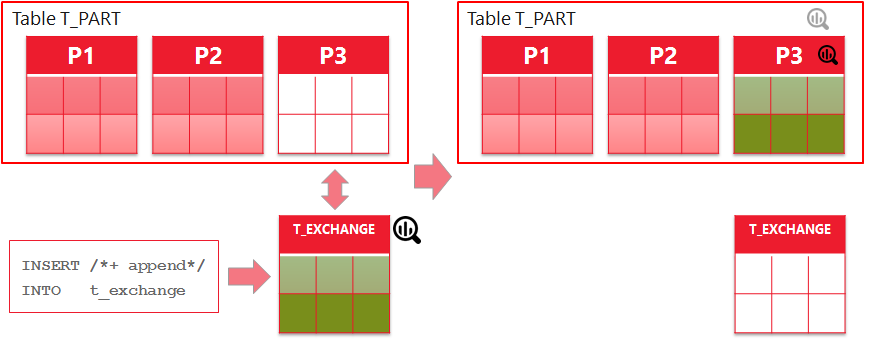
Figure 1: Partition Exchange Load
Let’s start creating a partitioned table T_PART, setting the INCREMENTAL preference for global statistics gathering to be TRUE, insert some data into one particular partition (P2) and gather table statistics. We can see partition level and global statistics:
SQL> CREATE TABLE t_part (pkey number, id number, s varchar2(20))
2 partition by range (pkey)
3 (partition P0 values less than (0),
4 partition P1 values less than (1),
5 partition P2 values less than (2),
6 partition P3 values less than (3));
Table T_PART created.
SQL> exec dbms_stats.set_table_prefs(null,'T_PART','INCREMENTAL','TRUE')
PL/SQL procedure successfully completed.
SQL> INSERT /*+ append */ INTO t_part PARTITION (P2)
2 SELECT 1 pkey, level AS id , lpad (level, 20, '0') s
3 FROM dual
4 CONNECT BY level <= 10000;
10,000 rows inserted.
SQL> COMMIT;
Commit complete.
SQL> begin
2 dbms_stats.gather_table_stats (null,'T_PART');
3 end;
4 /
PL/SQL procedure successfully completed.
SQL> SELECT table_name, partition_name, global_stats, last_analyzed, num_rows
2 FROM user_tab_statistics s
3 WHERE table_name IN ('T_PART');
TABLE_NAME PARTI GLOBA LAST_ANALYZED NUM_ROWS
---------- ----- ----- ------------------- ----------
T_PART P3 YES 28.10:2018 08:26:33 0
T_PART P0 YES 28.10:2018 08:26:33 0
T_PART YES 28.10:2018 08:26:33 10000
T_PART P2 NO 28.10:2018 08:26:33 10000
T_PART P1 YES 28.10:2018 08:26:33 0
Listing 3: Setup for partition exchange
Now let’s load data with partition exchange. First, we need a non-partitioned table with identical structure as our target table. Fortunately, if you are on 12.2, you can use just one DDL-command for this (line 2). It’s a new feature, see more in Oracle SQL Reference and also on Dani Schnider’s Blog. Also new in 12c (12.1) is the possibility to calculate synopsis on non-partitioned tables. To do so we have to set preferences INCREMENTAL to TRUE and INCREMENTAL_LEVEL to TABLE for our newly created table T_EXCHANGE (lines 6-10). After direct-path load into T_EXCHANGE we are now having table and basic column statistics along with synopsis (lines 25-50)
SQL> -- create a table for exchange (12.2 feature)
SQL> CREATE TABLE t_exchange FOR EXCHANGE WITH TABLE t_part;
Table T_EXCHANGE created.
SQL> BEGIN
2 dbms_stats.set_table_prefs (null,'t_exchange','INCREMENTAL','TRUE');
3 dbms_stats.set_table_prefs (null,'t_exchange','INCREMENTAL_LEVEL','TABLE');
4 END;
5 /
PL/SQL procedure successfully completed.
SQL> INSERT /*+ append */ INTO t_exchange
2 SELECT 2 pkey, level AS id , lpad (level, 20, '0') s
3 FROM dual
4 CONNECT BY level <= 10000;
10,000 rows inserted.
SQL> COMMIT;
Commit complete.
SQL> SELECT table_name, partition_name, global_stats, last_analyzed, num_rows
2 FROM user_tab_statistics s
3 WHERE table_name IN ('T_EXCHANGE');
TABLE_NAME PARTI GLOBA LAST_ANALYZED NUM_ROWS
---------- ----- ----- ------------------- ----------
T_EXCHANGE NO 28.10:2018 08:37:39 10000
SQL> -- Check Synopsis
SQL> SELECT o.name Table_Name,
2 c.name "Column",
3 h.analyzetime "Synopsis Creation Time",
4 h.bo#
5 FROM sys.WRI$_OPTSTAT_SYNOPSIS_HEAD$ h,
6 sys.OBJ$ o,
7 sys.COL$ c
8 WHERE o.name = 'T_EXCHANGE' AND
9 h.bo# = c.obj#(+) AND
10 h.intcol# = c.intcol#(+) AND
11 h.bo# = o.obj#
12 ;
TABLE_NAME Colum Synopsis Creation T BO#
---------- ----- ------------------- ----------
T_EXCHANGE PKEY 28.10:2018 08:37:39 74603
T_EXCHANGE ID 28.10:2018 08:37:39 74603
T_EXCHANGE S 28.10:2018 08:37:39 74603
Listing 4: Load data into exchange table and check the gathered statistics and synopsis
Now we are ready to exchange the table with partition and see what will happen with the statistics. Right after exchange operation we can see partition-level statistics for the new partition: they were just copied from the exchange table. Re-gather table statistics and we see also global statistics being updated (20000 rows). This happens without full scan of the table T_PART, just using the copied synopsis of the T_EXCHANGE (see highlighted lines 75-77)
SQL> -- Exchange the table with partition
SQL>
SQL> ALTER TABLE T_PART EXCHANGE PARTITION P3 WITH TABLE t_exchange
2 INCLUDING INDEXES WITHOUT VALIDATION;
Table T_PART altered.
SQL> SELECT table_name, partition_name, global_stats, last_analyzed, num_rows
2 FROM user_tab_statistics s
3 WHERE table_name IN ('T_PART');
TABLE_NAME PARTI GLOBA LAST_ANALYZED NUM_ROWS
---------- ----- ----- ------------------- ----------
T_PART YES 28.10:2018 08:26:33 10000
T_PART P3 NO 28.10:2018 08:37:39 10000
T_PART P1 YES 28.10:2018 08:26:33 0
T_PART P2 NO 28.10:2018 08:26:33 10000
T_PART P0 YES 28.10:2018 08:26:33 0
SQL> begin
4 dbms_stats.gather_table_stats (null,'T_PART');
5 end;
6 /
PL/SQL procedure successfully completed.
SQL> SELECT table_name, partition_name, global_stats, last_analyzed, num_rows
2 FROM user_tab_statistics s
3 WHERE table_name IN ('T_PART');
TABLE_NAME PARTI GLOBA LAST_ANALYZED NUM_ROWS
---------- ----- ----- ------------------- ----------
T_PART P2 NO 28.10:2018 08:26:33 10000
T_PART P0 YES 28.10:2018 08:26:33 0
T_PART YES 28.10:2018 08:41:21 20000
T_PART P3 NO 28.10:2018 08:37:39 10000
T_PART P1 YES 28.10:2018 08:26:33 0
SQL> SELECT o.name Table_Name,
2 p.subname Partition_name,
3 c.name "Column",
4 h.analyzetime "Synopsis Creation Time"
5 FROM sys.WRI$_OPTSTAT_SYNOPSIS_HEAD$ h,
6 sys.OBJ$ o,
7 sys.COL$ c,
8 ( ( SELECT TABPART$.bo# BO#,
9 TABPART$.obj# OBJ#
10 FROM sys.TABPART$ tabpart$ )
11 UNION ALL
12 ( SELECT TABCOMPART$.bo# BO#,
13 TABCOMPART$.obj# OBJ#
14 FROM sys.TABCOMPART$ tabcompart$ ) ) tp,
15 sys.OBJ$ p
16 WHERE o.name = 'T_PART' AND
17 tp.obj# = p.obj# AND
18 h.bo# = tp.bo# AND
19 h.group# = tp.obj# * 2 AND
20 h.bo# = c.obj#(+) AND
21 h.intcol# = c.intcol#(+) AND
22 h.bo# = o.obj#
23 ORDER BY 4,1,2,3
24 ;
TABLE_NAME PARTI Colum Synopsis Creation T
---------- ----- ----- -------------------
T_PART P0 ID 28.10:2018 08:26:33
T_PART P0 PKEY 28.10:2018 08:26:33
T_PART P0 S 28.10:2018 08:26:33
T_PART P1 ID 28.10:2018 08:26:33
T_PART P1 PKEY 28.10:2018 08:26:33
T_PART P1 S 28.10:2018 08:26:33
T_PART P2 ID 28.10:2018 08:26:33
T_PART P2 PKEY 28.10:2018 08:26:33
T_PART P2 S 28.10:2018 08:26:33
T_PART P3 ID 28.10:2018 08:37:39
T_PART P3 PKEY 28.10:2018 08:37:39
T_PART P3 S 28.10:2018 08:37:39
12 rows selected.
Listing 5: After partition exchange: all statistics are now on partitioned table
Incremental statistics on partitioned tables is an interesting topic on its own. Here are some useful links:
- Nigel Bayliss – Efficient Statistics Maintenance for Partitioned Tables Using Incremental Statistics – Part 2
- Nigel Bayliss – Efficient Statistics Maintenance for Partitioned Tables Using Incremental Statistics – Part 3
- Dani Schnider – Incremental Statistics – A Real World Scenario
What’s new in the cloud (ADWC)?
There are some significant changes (improvements) to online statistics gathering in Oracle’s Autonomous Data Warehouse Cloud (ADWC). By default, they will be gathered also if the data segment was not empty. Also column histograms will be calculated on the fly. These two behavior changes are controlled with new „underscore“ parameters, both TRUE by default:
„_optimizer_gather_stats_on_load_all“: controls loading into a non-empty target table.
„_optimizer_gather_stats_on_load_hist“: controls histograms calculation.
Looks very promising for me. Now, that we have also partitioning in ADWC, it might be nice, for example, to also gather histograms online while loading data into an exchange table and then take them over to a partitioned table.
By the way, „_optimizer_gather_stats_on_load_hist“ seems to be working also in 18c on-premises version. Of course, I don’t encourage you to use the undocumented parameter in your system. After all, we don’t know, whether it is a bug or intention. But I hope this might be an indication, that some day this feature will be activated for on-premises version too.