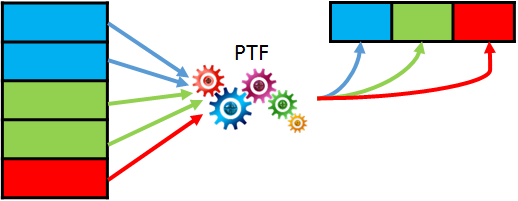
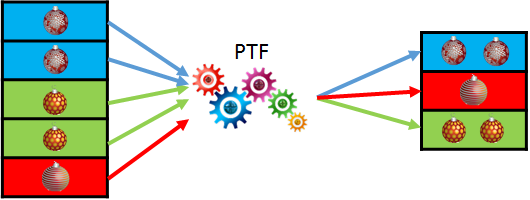
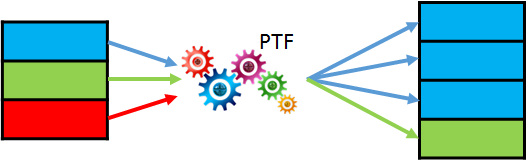
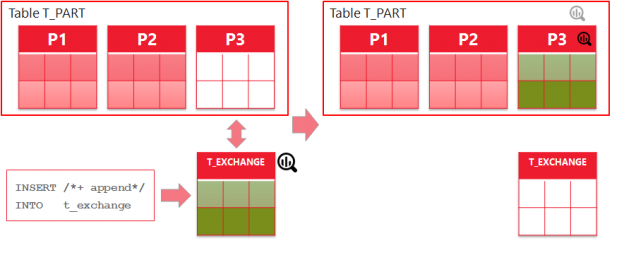
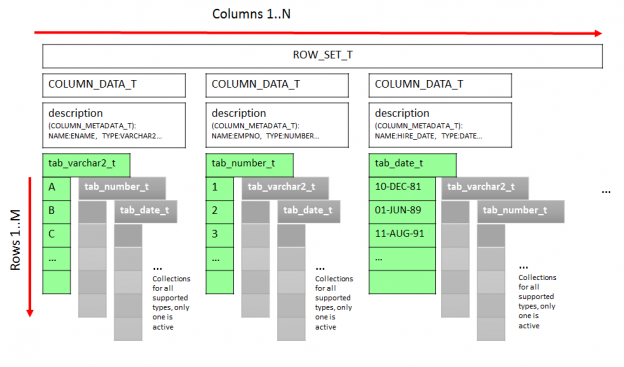
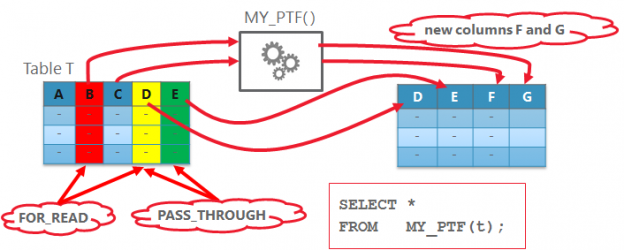
Performing an ETL with large data sets, it is often a good idea to run DML in parallel. But, in contrast to parallel query or DDL, parallel DML have to be explicitly enabled. You had to issue ALTER SESSION ENABLE PARALLEL DML in the past. Starting with 12c you can enable parallel DML specifically for each query using the hint ENABLE_PARALLEL_DML. For a few years now, I’ve been using the hint now and then and was quite happy. An observation I made a few days ago can lead to a rethinking. What I could observe is that for the SQL with embedded hint a new child cursor was created each time. Let’s test it! Weiterlesen
Issue with the Hint ENABLE_PARALLEL_DML
Schreibe eine Antwort